|
»ö« Welcome to Perl 6! | perl6.org/ | evalbot usage: 'p6: say 3;' or rakudo:, or /msg camelia p6: ... | irclog: irc.perl6.org or colabti.org/irclogger/irclogger_logs/perl6 | UTF-8 is our friend! Set by moritz on 22 December 2015. |
|||
|
00:03
AlexDani` joined
00:04
AlexDani` left
00:05
AlexDani` joined
00:06
holyghost left,
AlexDaniel left,
holyghost joined,
ctilmes left
00:07
ctilmes joined,
pmurias joined
00:11
AlexDani` is now known as Alexdaniel
|
|||
| Herby_ | given a file name, whats the best way to remove the extension from the name? | 00:20 | |
| test.txt, script.pl | |||
| i have a large amount of files, and they may have multiple '.' throughout the file names | 00:21 | ||
| basically i'm trying to print out file names to a textfile, without the extensions on them | 00:23 | ||
|
00:24
cioran89_ joined
00:28
cioran89 left
00:29
pmurias left
|
|||
| Alexdaniel | m: say ‘hello.tar.gz’.IO.extension(‘’, parts => ^999) | 00:31 | |
| camelia | "hello".IO | ||
| Alexdaniel | I really don't know | 00:32 | |
|
00:38
BenGoldberg joined
00:48
Rawriful left
00:49
Zoffix joined
|
|||
| Zoffix | m: 'foo.bar.ber'.split('.').head.say | 00:49 | |
| camelia | foo | ||
| Zoffix | Herby_: ^ | ||
| Just use split | |||
| Herby_ | nice! and grab everything except for the last element and join back to get the file name? | 00:50 | |
| for your example i'd want: foo.bar | |||
| Zoffix | Herby_: so you want to remove just the last part? | 00:51 | |
| Herby_ | yep. if I have script.pl, story.txt, I'd want to print out: script, story | ||
| but the file path might have multiple '.' in them | |||
|
00:52
Alexdaniel left
|
|||
| Zoffix | m: say ~.IO.extension: '' for <script.pl story.txt> | 00:52 | |
| camelia | script story |
||
| Herby_ | :) | ||
| Zoffix | Herby_: there are extensive docs for .extension routine: docs.perl6.org/routine/extension#(..._extension | ||
| It can handle the first case too, but it's way faster to just use split | |||
| Herby_ | gotcha | ||
| i was poking through the IO docs, figured there was a way but I didnt see it | 00:53 | ||
| i'll give this a shot, thanks! | |||
| Zoffix | m: say "foo.tar.gz".IO.extension: '', :parts(^Inf); | 00:54 | |
| camelia | Can only use numeric, non-NaN Ranges as :parts in block <unit> at <tmp> line 1 |
||
| Zoffix | boo... how in the world did that slip through like a gazillion tests | ||
| m: say "foo.tar.gz".IO.extension: '', :parts(0..Inf); | |||
| camelia | "foo".IO | ||
| Zoffix | :| | ||
| BenGoldberg | m: dd ^Inf; | 00:55 | |
| camelia | (0, 1, 2, 3, 4, 5, 6, 7, 8, 9... lazy list) | ||
| BenGoldberg | m: (^Inf).perl.say; | 00:56 | |
| camelia | 0..^Inf | ||
| BenGoldberg | m: (0..Inf).perl.say; | ||
| camelia | 0..Inf | ||
| BenGoldberg | m: say "foo.tar.gz".IO.extension: '', :parts(0..^Inf); | ||
| camelia | Can only use numeric, non-NaN Ranges as :parts in block <unit> at <tmp> line 1 |
||
| BenGoldberg | m: say "foo.tar.gz".IO.extension: '', :parts(0^..Inf); | ||
| camelia | Can only use numeric, non-NaN Ranges as :parts in block <unit> at <tmp> line 1 |
||
| Zoffix | m: dd (^Inf).minmax # <- reason | 00:58 | |
| camelia | Failure.new(exception => X::AdHoc.new(payload => "Cannot return minmax on Range with excluded ends"), backtrace => Backtrace.new) | ||
| Zoffix | LTA error too; it's only non-int ranges | 00:59 | |
| raschipi | Shouldn't .minmax detect that the ends are ^Inf and just treat them the same as Inf? | ||
| Zoffix | nope; it's not the max | 01:00 | |
| raschipi | m: dd (0..Inf).minmax | 01:01 | |
| camelia | (0, Inf) | ||
|
01:01
troys_ is now known as troys
|
|||
| raschipi | m: dd (0..^Inf).minmax | 01:01 | |
| camelia | Failure.new(exception => X::AdHoc.new(payload => "Cannot return minmax on Range with excluded ends"), backtrace => Backtrace.new) | ||
| raschipi | What's the difference between (0..Inf) and (^Inf)? | 01:02 | |
| Zoffix | raschipi: the former includes Inf, the latter doesn't | 01:03 | |
| ^5 is the same as 0..^5 is the same as 0..4 | |||
| raschipi | Right, but is there a difference when matching an Integer? | 01:04 | |
| Zoffix | Matching how? | 01:05 | |
| m: say 'foo.bar.ber.meow.moo'.IO.extension: '', :parts(0..^3) | 01:08 | ||
| camelia | "foo.bar.ber.meow".IO | ||
| Zoffix | m: say 'foo.bar.ber.meow.moo'.IO.extension: '', :parts(0..2) | ||
| camelia | "foo.bar.ber".IO | ||
| Zoffix | Another bug :( Zoffix-- | ||
| raschipi | Since we know there won't be an infinite number of extensions, I don't see why this kink in the interface should be as it is, it should just work... | 01:10 | |
| Zoffix | raschipi: I missed. Which kink? | 01:11 | |
| raschipi | That ^Inf doesn't work. | ||
| Zoffix | raschipi: ah, it's just a bug. Any value larger than 2⁶³-1 is treated as 2⁶³-1 | 01:12 | |
| I mean, it's a bug above. Normal behaviour is to use 2⁶³-1 as max | 01:13 | ||
| Oh, you mean .minmax? | |||
| Zoffix should probably go to bed :P | |||
| raschipi | I see, thanks. But I think minmax should have a way to do this for other similar cases. | ||
| Zoffix | You can use .min and .max + .excludes-min and .excludes-max to do the "^Inf is same as 0..Inf" semantics | 01:14 | |
| raschipi | Right, thanks. | 01:15 | |
|
01:16
aborazmeh joined,
aborazmeh left,
aborazmeh joined
01:26
Actualeyes joined
01:28
aborazmeh left
01:34
TEttinger left,
aborazmeh joined,
aborazmeh left,
aborazmeh joined
|
|||
| Herby_ | Zoffix: that extension worked like a champ for me and I was able to speed up my script dramatically because of it | 01:37 | |
| thanks :) | |||
| Zoffix | cool | 01:38 | |
|
01:38
TEttinger joined
01:43
Zoffix left
01:45
ilbot3 left
01:47
mr-foobar left,
ilbot3 joined,
ChanServ sets mode: +v ilbot3
01:59
troys is now known as troys_
02:11
mr-foobar joined
02:26
cioran89_ left
02:47
noganex joined
02:50
noganex_ left
|
|||
| pilne | confession: while learning perl5 past basic scripts and per -e stuff, i think i like ruby more, but perl6 still trumps everything else i've ever touched lol. | 02:51 | |
| araraloren_ | ruby is better perl :) | 02:52 | |
| pilne | that's what i enjoy about ruby, i can see where mattz got inspiration from perl, lisp, and smalltalk. | 02:56 | |
| i just get irked that most the wind in the community is web, and most of that is rails, i'm not a webdev, and i'm not realllllly a rails fan when i do poke at that stuff. | |||
| hobbs | I actually find ruby hard specifically because it does borrow so much from perl, but at the same time nothing is the same | 02:57 | |
| my brain goes "you can't do that with the @ sign!" and shuts down | |||
| pilne | i can survive, and enjoy the challenge of the code side and backend, but my interests are crypto, ai, roguelikes, game engines (logic stuff, not the display stuff). | 02:58 | |
| heh | |||
| i get something similar when i use python, except it is more like "wait, i can't just do that?" | |||
| no offense to python, it has a lot of good things about it (i feel most languages do have their good, especially if you consider when and why developed). | 02:59 | ||
| hobbs | that's what I mean, though, I'm more comfortable in python than ruby because at least python is wholeheartedly different :) | 03:00 | |
| pilne | if i had a stronger perl backround i would probably be the same, but my strongest are python/ruby, followed somewhat distantly by js, haskell, clojure, and racket. | 03:01 | |
| hobbs | yeah, gotcha | ||
| pilne | and i know enough java and c++ to stay away when i can (: | ||
| hobbs got paid to write perl for 10 years | |||
|
03:01
Cabanoss- joined
|
|||
| araraloren_ | yeah, I dont' like python, when you want some common feature, python: "sorry, i can't do that", like `switch case` `do while` .etc | 03:02 | |
| pilne | the funny thing is, i often looked to perlmongers and cpan when i got really stuck in those langages, for at least a conceptual direction to take python/ruby, because the community didn't really care about "a box" when it came to thinking about a problem, it just got done, period | ||
| raschipi | My problem with ruby doesn't have anything to do with the language itself. Their maintenece practices are bad: "just get the last version of this gem, we don't provide any long term support". | ||
| pilne | yeah, at least they are pretty hardcore about good testing. | 03:03 | |
| cpan's methodology is fucking awesome | 03:04 | ||
| raschipi | They got that right from Perl. | ||
| pilne | yeah, perl makes anyone else's testing look like a lint | 03:05 | |
| elses' | |||
| it's just not nearly as thurough and easy to ascertain... | |||
|
03:05
Cabanossi left,
Cabanoss- is now known as Cabanossi
|
|||
| raschipi | Documentation too, Perl blows everyone else out too, because CPAN doesn't allow devs to write a front page, it just shows the docs. | 03:06 | |
| pilne | so if you want to tell about the module, it better be doc'd. | ||
| araraloren_ | Of course doc is important | 03:07 | |
| raschipi | Compare that to ruby, where you get a very short description. | ||
| pilne | i really like it, and i'm damn amazed at how far the community has pushed it, my brain and perl5 just are having a hard time meshing. | ||
| araraloren_ | I dont' want check your code, and guess how to do.. | ||
| pilne | comments are docs are a fallicy IMHO, comments are for a general idea of what is doing what, and anything that is "quirky" compared to idiomatic code. | 03:08 | |
| raschipi | Now that P6 is migrating to CPAN and getting cpan-testers support, I expect they will get awesome too. | 03:09 | |
| hobbs | it's funny, POD is so unstructured compared to what many other languages have... and yet all of those structured documentation formats frequently leave you no good place to put information *other* than method docs, like rationales and tutorials and FAQs and references to similar tools and... :) | 03:10 | |
| pilne | i think cpanimus and zef are the only module tools i've used that run tests when installing a module. | ||
| hobbs | so the messiness leads to some nice things | ||
| pilne | i tend to do better when trying to learn perl5 if i see the code as a conversation. | 03:11 | |
| raschipi | I don't think POD are expected to be by-method exclusively even, exactly because it ends up as the CPAN front page. | ||
| *is expected | 03:12 | ||
| hobbs | raschipi: oh, definitely not :) | ||
| POD's main inspiration is clearly man pages | |||
|
03:12
gregf_ left
|
|||
| raschipi | man pages is generally way more terse than what usually comes in POD | 03:12 | |
| geekosaur | perl 5's main inspiration is common unix stuff including man pages | 03:13 | |
| raschipi | The closer is GNU info, I think. | ||
| hobbs | some man pages are, but looks at the common format... particularly utility manpages, not function ones | 03:14 | |
| NAME, SYNOPSIS, DESCRIPTION, OPTIONS, whatever other stuff, SEE ALSO, BUGS... :) | |||
| raschipi | The format is close, yes. Especially because it's made to be shown in the exact same way. | ||
| hobbs | the GNU folks are off on a whole other tangent | ||
| raschipi | I see. Yeah, just less terse. | 03:16 | |
| It is also installed as the man page for the module, of course. | 03:19 | ||
| hobbs | right | 03:20 | |
| and probably it's all because the ur-POD was perldoc perl which is also man perl | |||
| raschipi | Section 3pm of the manual. | 03:24 | |
| m: "/usr/local/man/man3".IO.dir.grep(/\.3pm/) | 03:27 | ||
| camelia | ( no output ) | ||
| raschipi | m: "/usr/local/man/man3".IO.dir.grep(/\.3pm/).say | ||
| camelia | () | ||
|
03:43
khw left
03:48
MasterDuke left
04:00
Cabanoss- joined
04:04
Cabanossi left,
Cabanoss- is now known as Cabanossi,
araujo left
04:06
fatguy joined
|
|||
| fatguy | how do i get exit status from qx ? | 04:08 | |
|
04:11
Sgeo joined
04:12
Sgeo__ left
04:18
fatguy left
|
|||
| moritz | use run(:out, $command) instead | 04:19 | |
| raschipi | He left | 04:21 | |
|
04:23
fatguy joined
|
|||
| raschipi | he,'s back | 04:25 | |
| fatguy: moritz said: use run(:out, $command) instead | 04:26 | ||
| fatguy | moritz: i tested using run, but the exitcode seems not right | ||
| ya raschipi | |||
| i tried : my $date= run "date", "x", :out; say $date.exitcode # this return 0, echo $? return 1 because -x option is not valid | 04:28 | ||
| zengargoyle_ | seeking p6 unicode wizards... how many diacritics vs latin chars in "ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước" | ||
| geekosaur | fatguy, you have to do something with $date.out first | 04:30 | |
| otherwise the process and its pipe are still in limbo and there is no exitcode | |||
| zengargoyle_ | that's apparently "antidisestablishmentarianism" in Vietnamese and the larger question is finding the word that uses latin alphabet + diacritics that has the most diacritics. :) | 04:31 | |
| geekosaur | zengargoyle_, keep in mind that (a) unicode gets normalized (b) internal format is graphemes | ||
| I think you have to get the .NFC form if you want to poke at diacritics, and then you have to beware that in NFC e.g. á is one codepoint | 04:32 | ||
| zengargoyle_ | yes, i was thinking of the .NFD or whatever thing it is that blows them up to codepoints or such. | ||
| geekosaur | I don't know if you can match just diacritics easily | ||
| moritz | fatguy: you need to close .out before the exit code becomes available, at the very least | ||
| raschipi | Can't help with your problem, words in Portuguese have at most two diacritics. | 04:33 | |
| geekosaur | fatguy, note that $date.out is *not* the output. it is an IO::Handle attached to a pipe. and that pipe has to be closed before you can get the exit status. | 04:35 | |
| zengargoyle_ | it's no big deal, just a question i saw on a question asking site where i thought OMG p6 should rock at this (if i can find a corpus or suitable text to check, which i imagine is probably the hardest part). | 04:36 | |
| geekosaur | (that isn;t really ideal but then the ideal requires you have a separate thread processing the output vs. waiting for the command to complete) | ||
| zengargoyle_, you probably want to ask samcv about this | |||
| samcv | hello | ||
| let me read the scrollback | 04:37 | ||
| zengargoyle_ | hehe, summoning is always fun. :) | ||
| fatguy | moritz: thanks, i able to get it with $date.out.close.exitcode | ||
| geekosaur: noted sir ! | 04:38 | ||
| samcv | ok. NFD will break it down into base characters + extend mark characters at least *if* it exists as a decomposible form. sometimes there is no decomposition. but for latin diacritics usually | ||
| but yes NFD should do what you want | |||
| m: "ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước".NFD.say | |||
| camelia | NFD:0x<0075 031b 0323 002d 0070 0068 0061 0309 006e 002d 0111 006f 0302 0301 0069 002d 0076 0069 0065 0323 0302 0063 002d 0074 0061 0301 0063 0068 002d 006e 0068 0061 0300 002d 0074 0068 006f 031b 0300 002d 0072 0061 002d 006b 0068 006f 0309 0069 002d 00… | ||
| samcv | :D | 04:39 | |
| goes from 45-> 61 codepoints if you use the Norm Form decomposition | |||
| zengargoyle_ | how do i do the matching for latin? i tried to grep those for * < 127 and it didn't seem to work out. | 04:40 | |
| samcv | m: "ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước".NFD.list.grep({.uniprop('GCB') eq 'Other' }).say | 04:41 | |
| camelia | (117 45 112 104 97 110 45 273 111 105 45 118 105 101 99 45 116 97 99 104 45 110 104 97 45 116 104 111 45 114 97 45 107 104 111 105 45 110 104 97 45 110 117 111 99) | ||
| samcv | ok those are all the "normal" characters | ||
| m: "ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước".NFD.list.grep({.uniprop('GCB') eq 'Other' }).chrs.say | |||
| camelia | u-phan-đoi-viec-tach-nha-tho-ra-khoi-nha-nuoc | ||
| zengargoyle_ | nm think i may have thinko'd on my test. | ||
| samcv | well normal as far as they are base characters | 04:42 | |
| though if you used emoji doing that would miss emoji base characters but. i think that's beside what you're doing | |||
| thinko'd? | |||
| zengargoyle_ | samcv++ thanks for the insight. | 04:43 | |
|
04:43
lizmat left
|
|||
| zengargoyle_ | typo'd, thinko'd | 04:43 | |
| raschipi | Then count what changed to know how many had diacritics. | ||
| u: đ | |||
| samcv | yep | ||
| unicodable6 | raschipi, U+0111 LATIN SMALL LETTER D WITH STROKE [Ll] (đ) | ||
| zengargoyle_ | i had my .grep after a .elems and missied it. :P | ||
| samcv | or are you counting diacrititcs or nuumber of characters which have diacritics on them | 04:44 | |
| characters can have multiple diacritics | |||
| or is that irrelevant for our uses | |||
| zengargoyle_, using GCB will be better than sorting <127 as you can see | |||
| otherwise you'd lose that fancy d | |||
| zengargoyle_ | Many languages add diacritics or special characters to the Latin alphabet. What word—a real word, not a made-up one—contains the most such characters? | ||
| samcv | đ | ||
| and đ doesnt't decompose | |||
| so i guess you could count that one manually | 04:45 | ||
| zengargoyle_ | the question isn't really that specific at the moment... | ||
| samcv | :P | ||
| but i see if you're only looking at vietnames | |||
| raschipi | 'đ' is to 'd' what 't' is to 'l' | ||
| zengargoyle_ | the vietnamese was just the first answer sombody posted. i don't even know if it's a correct example yet. :) | 04:46 | |
| samcv | m: my $s = "ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước"; my $s1 = $s.NFD.list.grep({.uniprop('GCB') eq 'Other' }); $s.NFD.elems - $s1.elems + $s1.grep({$_ > 127}).elems.say | 04:47 | |
| camelia | WARNINGS for <tmp>: Useless use of "+" in expression "- $s1.elems + $s1.grep({$_ > 127}).elems.say" in sink context (line 1) 1 |
||
| samcv | m: my $s = "ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước"; my $s1 = $s.NFD.list.grep({.uniprop('GCB') eq 'Other' }); say $s.NFD.elems - $s1.elems + $s1.grep({$_ > 127}).elems | ||
| camelia | 17 | ||
| samcv | there you go :) | 04:48 | |
| that also accounts for things that do not decompose | |||
| GCB=Other that don't decompose that is | |||
| zengargoyle_ | sweet. | 04:49 | |
| samcv | i feel proud now heh | ||
|
04:49
fatguy left
|
|||
| samcv | was fun to solve | 04:49 | |
|
04:50
lizmat joined
|
|||
| raschipi | I remember there was a function that stripped diacritica, but can't remember the name now... | 04:51 | |
| samcv | and that should count the number of diacritics themselves as opposed to the number of characters which have diacritics (which you'd be counting if you did $s.chars.grep({$_> 127}).elems | ||
| raschipi, in perl6? | |||
| raschipi | Yeah | ||
| samcv | or do you mean ignoremark regex or something | ||
| though that doesn't strip them, but allows you to match them | 04:52 | ||
| raschipi | You gave it a charachter with a diacritic and it applied that diacritic to some other character. | ||
| samcv | ugh that reminds me. how ignoremark and ignorecase together doesn't always work. eek working on that scares me thinking | ||
| oh | |||
| raschipi | Or if you gave it a charachter without a diacritic, it took them away. | ||
| samcv | i think i remember something | ||
| i forget what it is though but it sounds familiar | |||
| raschipi | That way it can be done without messing with bytes. | 04:53 | |
| pilne | either zoffix's slides or the perl6intro list the "length of a unicode" functions, i recall there being three, but i can't remember their smeggin names atm, the high ABV is catching up quick | 04:54 | |
| moritz | EastAsianWidth or something like that? | 04:55 | |
| raschipi | samemark is the name | 04:57 | |
| samcv | oo yep that's it | ||
| raschipi | m: 'a'.samemark('ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước') | 04:58 | |
| camelia | ( no output ) | ||
| raschipi | m: 'a'.samemark('ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước').say | ||
| camelia | ạ̛ | ||
| raschipi | Other way around | 04:59 | |
| samcv | it's cool. not sure when i'd use it. but can't hurt having more exciting things :P | ||
| i'm sure it will be really useful for someone somewhere. and save them loads of time | |||
| raschipi | m: 'ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước'.samemark('a') | ||
| camelia | ( no output ) | ||
| raschipi | m: 'ự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước'.samemark('a').say | ||
| camelia | u-phan-đoi-viec-tach-nha-tho-ra-khoi-nha-nuoc | ||
| samcv | 'đ'.samemark('a').say | 05:00 | |
| m: 'đ'.samemark('a').say | |||
| camelia | đ | ||
| samcv | yeah so if it can't decompose it just keeps it | ||
| raschipi | People strip diacritics to filter expletives, for example. | ||
| samcv | i wonder... how it works with Prepend characters. since i just added support to MVM recently for that. i bet it may break | ||
| or it could work depending. | |||
| before unicode 9.0, diacritics always came *after* the base character. | 05:01 | ||
| with prepend marks. they throw that outh the window and come before | |||
| in any case. should have something added to roast to test it even if it doesn't work atm | |||
| raschipi | That will get the trolls going... | ||
| samcv | prepend marks? | 05:02 | |
| raschipi | Yeah. | ||
| The unicode-haters. | |||
| samcv | heh | ||
|
05:02
parv joined
|
|||
| raschipi | That think ASCII is good enough for them and everyone else in the world can keep the mess that are locale-specific encodings. | 05:03 | |
| samcv | boring! | ||
| raschipi | The other day there was one that said Perl6 should drop Unicode support. I said he should try to convince Larry to not be able to write Chinese and French on the same file. | 05:04 | |
| samcv | i wonder if i should roll ignoremark and case insensitive regex into my grant | ||
| i didn't plan to include it in there. but i think it would achieve many of the things my grant seeks to do | |||
| raschipi | I think you must do it. | 05:05 | |
| samcv | even if it takes me a little longer to complete | ||
| yeah i agree | |||
| pilne | unicode is the future, ignoring it is the ostrich solution | ||
| samcv | dodo? | ||
| raschipi | Ask for more money. | ||
| samcv | i probably won't. i mean the money is mostly so i can 1. do some of the less fun parts of the unicode retrofit and 2. be able to hold off on getting a job for a while longer and keep working on perl 6 | 05:06 | |
| since i do very much enjoy contributing | 05:07 | ||
| parv | samcv++ thanks for your work. | 05:08 | |
| samcv | you're very welcome | ||
|
05:09
aborazmeh left
|
|||
| zengargoyle_ | yay samcv++ again for good measure. :) | 05:28 | |
|
05:31
troys_ is now known as troys
05:59
fatguy joined
06:07
wamba joined,
troys is now known as troys_
06:16
pilne left
06:17
BenGoldberg left
06:25
espadrine_ joined
|
|||
| TEttinger | huh, I'm curious what all that vietnamese text was up there | 06:39 | |
| supporting vietnamese is a win-nguyen | |||
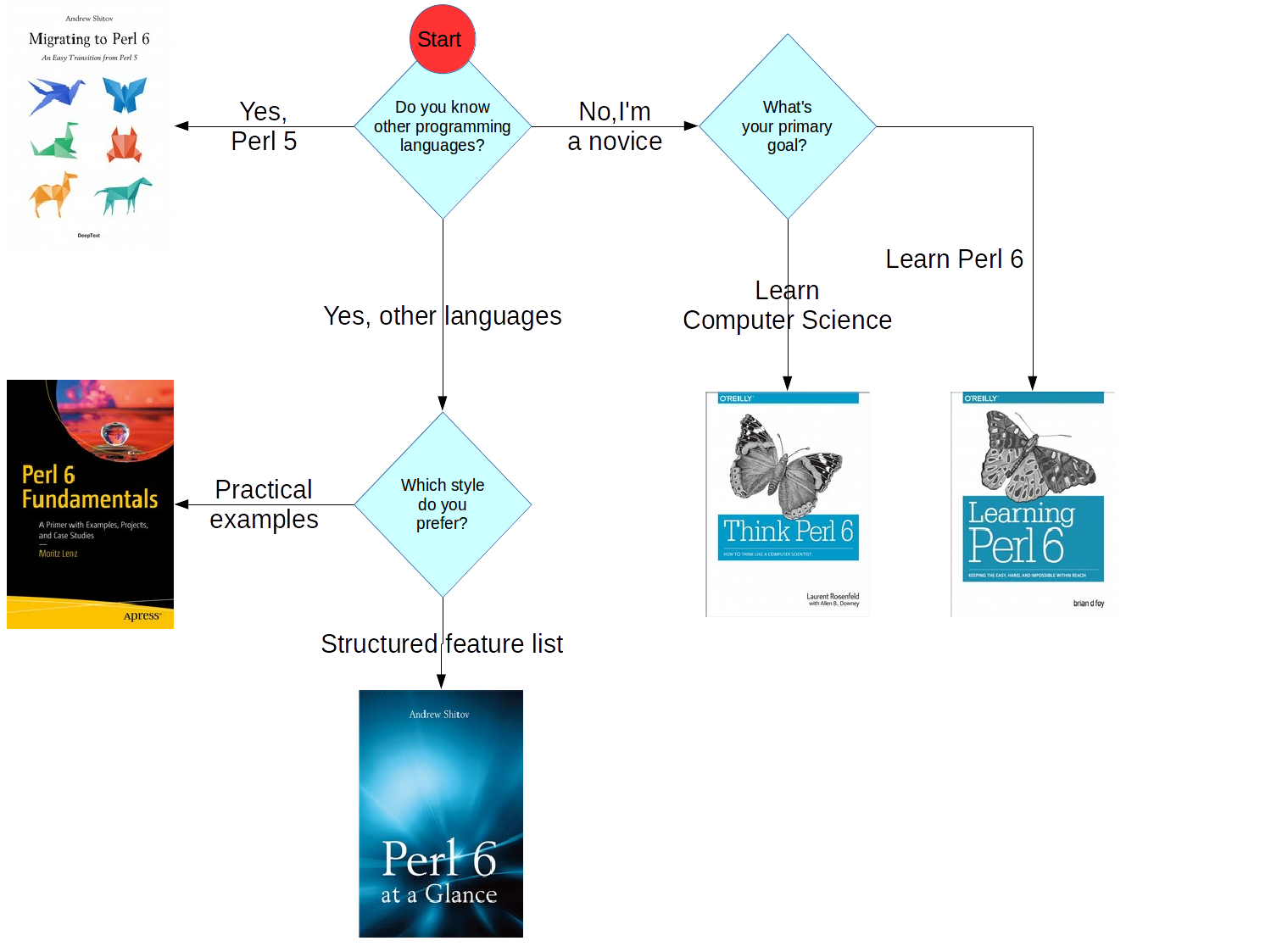
| moritz | oh hai. Here's my Perl 6 book decision tree as an image: github.com/moritz/perl6book-web/bl...ree/v1.png | 06:43 | |
| feedback welcome | |||
|
06:43
fatguy left
|
|||
| TEttinger | might want a "start here," though it is pretty clear | 06:43 | |
| moritz | (or improvements; the libreoffice source file sits right next to it in the same directory) | 06:44 | |
| TEttinger | which did you write? | 06:45 | |
| moritz | if you can't tell from the chart, that's good :-) | ||
| Fundamentals | |||
| TEttinger | oh, that was my guess | ||
| practical is something of a weasel word, in wikipedia parlance | 06:46 | ||
| moritz | what would you use instead? | ||
| TEttinger | it's just none of the others had qualifiers | ||
| other than "structured" | 06:47 | ||
| I think it's fair | |||
| you aren't writing wikipedia, you're writing a book :) | |||
| moritz | I wouldn't want to add "constructed examples" to "Perl 6 at a Glance" though :) | ||
| TEttinger | practical examples in what fields? | 06:48 | |
| scripts for handling sysadmin tasks? | |||
| complex text parsing and handling? | 06:49 | ||
| moritz | different fields: sysadmin, data visualization, Unicode research, parsing | ||
| TEttinger | I'm not sure how practical unicode research is, since as samcv was saying they can change the rug while you're standing on it, as with prepend marks | ||
| they being unicode consortium | 06:50 | ||
| but if it's like census data where there's a ton of languages at play, sure | |||
| moritz | Unicode research as in "how do I find (about) character XY?" | 06:51 | |
| parv | moritz, both of "Do you know other ..." & "primary goal" rhombii look to be perfectly good starting places but the arrow connecting the two is unidirectional | 06:58 | |
| s/rhombii/rhombi/ | 06:59 | ||
| moritz | parv: do you think there should be an explicit staring point? | 07:10 | |
| parv | moritz, depends on how formal you want to be. i don't have enough formal comp sc background & have used perl 5 for 10+ years | 07:12 | |
| moritz | raw.githubusercontent.com/moritz/p...ree/v1.png now with an obvious start marker | 07:15 | |
| parv | "Do you know .." could point to "No, learn comp sc" and "No, learn perl 6". "primary goal" could be another starting place, and pointing to "learn comp sc" & "learn perl " | 07:16 | |
| ok, that works too | 07:17 | ||
|
07:19
TEttinger left
07:20
TEttinger joined
|
|||
| parv | moritz, is (would) there (be) a reference book? or, would that be too early due to changes in rakudo? | 07:21 | |
| raschipi | parv: There are rumors that TIMTOWDY is working on a reference book. | 07:23 | |
| parv | "perl 6 at a glance" does it list classes, methods; regex building, etc? | 07:24 | |
| moritz | parv: the closest we come to reference material is doc.perl6.org | ||
| parv | raschipi, oh sweet. | ||
| moritz | raschipi: more like "programming perl 6" | ||
|
07:24
sammers joined
|
|||
| parv | thanks moritz. | 07:24 | |
| moritz | I don't see much value in a reference in book format | 07:25 | |
| sammers | hi all | ||
| moritz | which print several hundred pages of built-in class and method documentation when it's so much easier to search and look up in electronic form? | ||
| hi sammers | |||
| s/which/why/ | |||
| araraloren_ | hi | 07:26 | |
|
07:26
araraloren_ is now known as araraloren
|
|||
| raschipi | o/ | 07:26 | |
| parv | ho | ||
| sammers | question about the ==> feed behavior, in comparison to the . chaining behavior... | 07:29 | |
| m: sub foo($a, $b) { "We have: $a" }; "This should be a".&foo("this should be b").say; | |||
| camelia | We have: This should be a | ||
| sammers | chaining assigns the Str to $a, then the Str pass via &foo assigns it to $b | 07:30 | |
| m: sub foo($a, $b) { "We have: $a" }; "This should be a" ==> foo("this should be b") ==> say(); | |||
| camelia | We have: this should be b | ||
| sammers | but the ==> feed operator ignores the piped Str | 07:31 | |
| some other languages that have this sort of piping assign the value piped to the function to the first parameter | 07:32 | ||
| like the . chaining version | |||
| araraloren | In perl6 it's last | ||
| docs.perl6.org/routine/==%3E | |||
| sammers | ah | 07:33 | |
| ok, that works | |||
| does anyone know what the decision was to use a different behavior between the two? | 07:35 | ||
| araraloren | I dont' know, if there has a <== it would be work as you expect | 07:37 | |
| And it has | |||
| docs.perl6.org/routine/%3C== | |||
| raschipi | sammers: Perl6 functions want the data to be manipulated to be on the last parameter, like shell commands | 07:39 | |
| The dot uses a special first slot that functions know to treat differently. | 07:40 | ||
| sammers | raschipi, that makes perfect sense | ||
| araraloren | Oh, but that opereator not what you wanted. | ||
| raschipi | multi sub comb(Str:D $matcher, Str:D $input, $limit = Inf) | 07:41 | |
| multi method comb(Str:D $input:) | |||
| The method version has : after Str $input | |||
| That means it's a method that can be called in Str objects | 07:42 | ||
| araraloren | Oh, that was compatible to method. | 07:43 | |
| raschipi | So, the first thing to note is that when you use ==>, you're using a different version than when you use . | ||
|
07:43
nadim joined
|
|||
| raschipi | ==> calls a suroutine that expects the data on the end, . calls a method that expects the data at the start. | 07:43 | |
| That's why ==> puts the data at the end and . puts the data at the start. | 07:44 | ||
| I think languages that put it at the start don't have multiple dispatch like this? | |||
| araraloren | .& | 07:47 | |
| sammers | something like elixir for example does the data at start after |> | ||
|
07:47
CacoS joined
|
|||
| raschipi | sammers: Did you knew about multidispatch? | 07:48 | |
| sammers | yeah | ||
| raschipi | So, the secret is that they call different versions. | 07:49 | |
|
07:49
TEttinger left
07:54
darutoko joined
|
|||
| sammers | raschipi, thanks for explanation, makes sense | 07:57 | |
| araraloren | seems like I misunderstand what you said, sorry :P | 08:00 | |
| zengargoyle_ | .tell samcv diacritic counting went over well. now looking for good word lists. | ||
| yoleaux | zengargoyle_: I'll pass your message to samcv. | ||
| samcv | :-D | ||
| yoleaux | 08:00Z <zengargoyle_> samcv: diacritic counting went over well. now looking for good word lists. | ||
| samcv | i'm curious what you find! | 08:01 | |
| and yes perl 6 is the best language to do this in :-D | |||
| raschipi | Because of your work, samcv++ | ||
| zengargoyle_ | and any p6 peeps who might speak a language with a lot of latin-ish characters and a bunch of funny diacritics who know about a /usr/share/words type of source material.... | 08:02 | |
| curious minds want to know. :) | 08:03 | ||
| raschipi | I got this link: docs.perl6.org/syntax/&?ROUTINE but it returns a 404 | ||
| moritz | raschipi: which did you get that link from? | ||
| ah, from the search box | 08:04 | ||
| please open an issue: github.com/perl6/doc/blob/master/C...rting-bugs | |||
| samcv | thx raschipi | ||
| that's interesting. we have other links with & and ? that are fine | 08:05 | ||
| pls report :) | |||
| araraloren | docs.perl6.org/routine/.& also 404 | ||
| zengargoyle_ | a 22k list of common Vietnamese and a 60k of words from movie subtitles didn't come close to the person who knew 'antidisestablishmentarianism'. :P | 08:06 | |
| parv | WTF? | 08:07 | |
| lol | |||
| zengargoyle_ would have probably majored in linguistics if i had known there was such a thing when i went of to college. | 08:09 | ||
| raschipi | I don't know how to add a label on github issues. | 08:14 | |
| github.com/perl6/doc/issues/1358 | |||
| sammers: Have a look at this: docs.perl6.org/language/operators#...fix_.& | 08:21 | ||
| sammers | raschipi, thanks, that was my first example | 08:22 | |
| m: sub foo($a, $b) { "We have: $a" }; "This should be a".&foo("this should be b").say; | |||
| camelia | We have: This should be a | ||
| sammers | what does that mean? "Technically this is not an operator, but syntax special-cased in the compiler."? | 08:23 | |
| raschipi | Do you think it should be the last argument in that case? | ||
| sammers | I mean, I understand the words, but whas is the impact of that? | ||
| actually, I don't have a preference, I just wish it was consistent between ., .&, ==>, and <== | 08:24 | ||
| three of those are first param, only ==> is last | 08:25 | ||
| araraloren | No, <== is last parameter too, but to pass from right to left | 08:31 | |
| sammers | right, but from the sub signature definition perspecive it is also the first parameter. | 08:34 | |
| in all of those situations, except for ==>, we can create a routine, sub foo($first, $second, ...) and the piping / chaining will behave the same. | 08:35 | ||
| araraloren | I have no problem with ==>. It's fine, whether last or first. | 08:38 | |
|
08:39
rindolf joined
|
|||
| sammers | araraloren, right, not going to lose any sleep over it. understanding the behavior clears it up. | 08:45 | |
| araraloren | yeah, ^_< | 08:46 | |
| raschipi | g'night people | 08:55 | |
|
08:55
raschipi left
|
|||
| parv | bye | 09:07 | |
|
09:20
bpmedley left
09:33
parv left
|
|||
| samcv | zengargoyle_, but is that word actually a real word though | 09:44 | |
| like a Vietnamese person would say it is a word | |||
|
09:50
vetmaster joined
|
|||
| vetmaster | hi! | 09:50 | |
| I try to run the Euclidean algorithm, but the error "can't assign an immutable variable" occurs | 09:51 | ||
| ideone.com/lWJ3ic | |||
| if I'd like to reassign a function argument, how can I do this? | |||
|
09:52
Rawriful joined
09:53
Alexdaniel joined
|
|||
| vetmaster | I see a similar bug there rt.perl.org/Public/Bug/Display.html?id=130855 | 09:57 | |
| samcv | vetmaster, you want `is copy` | 09:58 | |
| sub euclidean (Int $a is copy, Int $b is copy) | 09:59 | ||
| because otherwise you try and assign to the number itself | |||
| if you passed in a variable you could write to it by setting it with ($a is rw) | |||
| but since you are passing in the number itself. it needs is copy, so you are then working with a variable not an immutable number | 10:00 | ||
| vetmaster | samcv: thank you, it works!! | 10:01 | |
|
10:16
wamba left
10:23
holyghost left
10:27
wamba joined
10:31
darutoko left
|
|||
| vetmaster | ideone.com/X3t1Uj | 10:38 | |
| I want to make a simple grammar to parse a cookie string | |||
| but I get an error on the line 8 | 10:39 | ||
| I want to set a key-value pair | |||
| <name>, '=' sign and <content> | |||
| but it doesn't work | |||
|
10:45
araraloren_ joined
10:46
araraloren left
|
|||
| araraloren_ | :( | 10:46 | |
|
10:46
araraloren_ is now known as araraloren
10:52
awwaiid left
|
|||
| zengargoyle_ | samcv: i have no clue about the veracity of the Vietnamese word. and i'm not sure about the dashes, i just assume that somebody who could type it (or even cut-n-paste it) has some idea that it's an actual word... :) | 10:55 | |
| Japanese (and i think Chinese) pretty much don't use spaces at all, so what's a word boundry is *much* harder than just splitting on spaces. | 10:57 | ||
| so i'm just assuming that's one utterance that carries some meaning that maps as close to a word. probably should exclude the '-' though. | 10:59 | ||
| vetmaster | this doesn't work too ideone.com/ansmt2 | ||
| jnthn | The error says why | 11:02 | |
| The , must be quoted | |||
| ','* | |||
| moritz | you probably meant ',' instead of <,> | ||
| jnthn | There's a nicer way to write this though | 11:03 | |
| Well, depending on exactly what you want to match | 11:04 | ||
| Instead of the ','* in pair, you can do <pair>* % [','+] | |||
| Where % means "separated by" | |||
|
11:06
vetmaster left,
vetmaster joined
|
|||
| vetmaster | jnthn: thank you, it works! | 11:07 | |
| ideone.com/ansmt2 | |||
| and yet another question.. | |||
| '<key> \h* '=' \h* <value>' | |||
| is \h* = \h* the nicest solution? | 11:08 | ||
| zengargoyle_ totally confused because i saw the first link after it was corrected. :) | |||
| timotimo | vetmaster: you can also use (\h*) ** 2 % '=' :) | ||
| moritz | vetmaster: it's nicer to use a token ws { \h* }, and then use a rule that automatically inserts ws calls where there's whietspace | ||
| timotimo: I find that... slightly more obscure :-) | 11:09 | ||
| vetmaster | many thanks :-) | 11:10 | |
|
11:18
labster left
|
|||
| zengargoyle_ | hehe, vdict.com/ (Vietnamese - English - French - Chinese Dictionary) barfs on "antidisestablishmentarianism" but i sorta guess that's to be expected. :P | 11:19 | |
| moritz | I've yet to find a DE <-> EN dictionary that contains "Frischdampfschnellschlussschieber" :-) | 11:22 | |
|
11:25
eliasr joined
11:26
vetmaster left
11:28
Alexdaniel left
|
|||
| moritz | general rant time: templates (like for producing HTML) make quite some assumptions on the data structures passed to them | 11:28 | |
| so, the're some kind of interface, or API | |||
| and in "regular" programming, we have tools for validating data at interfaces (like, uhm, types and stuff) | 11:29 | ||
| zengargoyle_ | google translate to the rescue! Sự-phản-đối-việc-tách-nhà-thờ-ra-khỏi-nhà-nước -> The protest-the-separation-of-church-out-of-state house | ||
| moritz | yet most template systems I've seen don't even attempt to provide any kind of tools for formalizing this API | 11:30 | |
| zengargoyle_: are they protesting *for* or *against* separation of church or state? :-) | |||
| those subtleties get lost in translation so easily | |||
| zengargoyle_ | still don't know what "Live steam quick-closing slide" means. :P | ||
| moritz | zengargoyle_: more like fresh steam quick-closing valve; part of safety equipment of power plants | 11:31 | |
| zengargoyle_ | heh. | 11:32 | |
| all i got was schnell from many hours of Hogan's Heros | |||
| moritz | German has this beautiful capacity to concatenate words nearly endlessly | ||
| zengargoyle_ | and the joke only comes at the end. | 11:33 | |
| moritz | like all good jokes :-) | ||
| zengargoyle_ | since google handled the Vietnamese translation to a margin of understandability, i'm going to just guess that spaces/dashes separating syllables are a lexical convenience and that is a cromulent Vietnamese 'word'. | 11:43 | |
|
11:46
hchienjo joined
|
|||
| zengargoyle_ | which brings up the horror of actually needing a list of 'words' or trying to parse semantics to find 'word' boundries vs just splitting on spaces which makes the whole question really hard. :) | 11:46 | |
| 'cause i don't grok how many foreign languages work. :P | 11:47 | ||
| huf | i wouldnt trust google translate at all | 11:55 | |
| the ridiculous sort of error rate is massive | |||
| eg, this seems to produce sensible results, but in fact it's ridiculous nonsense: translate.google.com/#auto/en/mert...0beszeltek | 11:56 | ||
| same: translate.google.com/#hu/en/k%C3%B...g%20bazmeg | |||
| also weird and impossible to trust: translate.google.com/#hu/en/vid%C3%A9k%20bazmeg | 11:57 | ||
| this is a rather big miss too: translate.google.com/#auto/fr/Alwa...to%20quit. | |||
| this is surreal: translate.google.com/#auto/en/m%C3%B3ricka | |||
| zengargoyle_ started firestorm, oops. | 12:03 | ||
| there's a reason why google translate was the *last* thing i checked. and a reason why i trusted someone who said "X eq Y" and then i thought 'OK, close enough'. | 12:05 | ||
| i don't really trust google translate either. | 12:06 | ||
| last resort. | |||
|
12:10
vetmaster joined
|
|||
| zengargoyle_ | i'd like to know how far off google translate was for your phrases, but i doubt many others would here in the #perl6 | 12:13 | |
| huf | zengargoyle_: "shitty language" somehow mysteriously became "soviet language", things like that. | ||
| zengargoyle_: a homophobic slur becomes a plain, unthreatening "hey" | 12:14 | ||
| and the diminutive for the local variant of the name moritz becomes "dream about", even though the word dream is "álom" | |||
| these are just the random gtranslate fails i grepped out of my irc logs :) | 12:15 | ||
| zengargoyle_ | ah, could you reasonably understand the translation even if it wasn't exactly correct. | ||
| huf | no, the translations make some kind of sense sometimes (not the same sense as the original, mind you) but you dont know how big the error is, so you cant be confident at all | 12:16 | |
| nine | Google translate can also give scarily accurate translations. Down to picking the right words for the scientific field. Since it's based entirely on statistical analysis, I guess it just works much better on longer texts. | 12:18 | |
| zengargoyle_ | i'd guess i could spout some regional slang at translate and have it go horribly wrong. | ||
| and i guess i just go for nouns and verbs and try to understand a bit. | 12:19 | ||
| "Slackjawed redneck motherf*cker" -> JP -> EN -> "Slack Jockey country grandmother." :P | 12:21 | ||
| nine | you typo'ed "motherfucker", no wonder it's not accurate ;) | 12:22 | |
|
12:24
vetmaster left
|
|||
| zengargoyle_ is a southern gentleman 40 years removed. | 12:26 | ||
| moritz | 14:14 < huf> and the diminutive for the local variant of the name moritz becomes "dream about", even though the word dream is "álom" | 12:35 | |
| now I get to call myself a certified dreamer :-) | |||
| zengargoyle_ | hehe, it'd totally take 'dream about' too. :) | 12:36 | |
| moritz | huf: btw what language is that, and what's the diminutive? | 12:37 | |
| huf | moritz: hungarian, and as it said in the link, móricka | 12:42 | |
| moritz: also a standard character in many jokes | |||
| he's the joker. pistike is the fuckup. :D | 12:43 | ||
|
13:09
domidumont joined
13:10
cdg joined
13:12
araraloren_ joined
13:13
fraya joined
13:14
domidumont left,
domidumont joined,
araraloren left
13:28
zakharyas joined
13:40
araralonre__ joined
13:42
Alexdaniel joined,
araraloren joined
13:43
araraloren_ left
13:44
mcmillhj joined,
araralonre__ left
13:45
fraya left
13:53
damnlie left
13:56
domidumont left
13:59
mr-foobar left
14:03
mr-foobar joined
14:05
kaare_ left
14:12
ajb joined
|
|||
| ajb | p6: "ac b" ~~ /\w+ % \s/ | 14:13 | |
| camelia | ( no output ) | ||
| ajb | p6: "ac b" ~~ /\w+ % \s/; $/.say | ||
| camelia | 「a」 | ||
| ajb | p6: "ac b" ~~ /[\w+]+ % \s/; $/.say | 14:14 | |
| camelia | 「ac b」 | ||
|
14:15
ajb left
14:16
pilne joined
14:21
fraya joined
|
|||
| moritz | perl6book.com/new/ now with a bit of CSS | 14:23 | |
| timotimo | moritz: have you considered using flexbox for the individual books? | 14:24 | |
|
14:24
pmurias joined
|
|||
| moritz | timotimo: I've heard of flexbox as a buzzword, but never learned it | 14:24 | |
| timotimo: what would it do? | |||
| nadim | .seen azawawi | 14:25 | |
| yoleaux | I saw azawawi 27 May 2017 12:50Z in #perl6: <azawawi> jnthn: in Graphics::PLplot im aiming on providing Raw (native) and cooked with sugar API :) | ||
| timotimo | moritz: it'd let multiple boxes sit in a row and depending on how much space there is it'd be more or fewer per row | ||
| moritz | timotimo: do I have to define a fixed width for that? | 14:26 | |
| pmurias | moritz: you can center stuff without ugly hacks | ||
| nadim | sunny Sunday to all, does anyone know where azawawi usually lurks? | 14:27 | |
| timotimo | nope, no fixed width needed | ||
| moritz | can I can declare that I want them all to have the same width, without defining the width myself? | 14:29 | |
.oO( I guess I should just google it) |
|||
|
14:29
araraloren_ joined
|
|||
| timotimo | hm, that's a good question | 14:31 | |
| that might not be possible | |||
| it could work if you go from "multiple things per row" to "multiple things per column" | 14:32 | ||
|
14:32
araraloren left
14:33
araraloren_ is now known as araraloren
|
|||
| moritz | perl6book.com/new/ | 14:35 | |
| updated | |||
| how do I get it to wrap? | |||
| mst | pay it 50 cents? | 14:36 | |
| moritz | it seems to ignore the flex-wrap: row | 14:37 | |
| mst | I know just enough about CSS to know I have no idea how any of it works, so I'm afraid terribad puns are the only assistance I can offer | 14:38 | |
| moritz | so I figured :) | 14:39 | |
| ah, it's called "flex-wrap: wrap", not "flex-wrap: row" | 14:42 | ||
|
14:42
araraloren_ joined
|
|||
| araraloren_ | :( | 14:43 | |
| moritz | chromium++ # the dev tools explained the error to me | ||
| mst | araraloren_: do we need to get duct tape for your connection? | 14:44 | |
| araraloren_ | haha, no :) | ||
|
14:46
araraloren left
|
|||
| moritz | perl6book.com/new/ updated | 14:48 | |
|
14:51
khw joined,
awwaiid joined
14:53
kaare_ joined
14:57
mcmillhj left
14:59
hchienjo left
15:01
cdg left,
cdg_ joined
15:02
ctilmes left
15:04
fraya left
15:13
rindolf left
|
|||
| moritz | ... now moved to perl6book.com/ | 15:13 | |
|
15:18
Alikzus_ left,
rindolf joined
15:23
Alikzus_ joined
15:33
troys_ is now known as troys
|
|||
| pmurias | the Perl 6 book market seems crowded | 15:35 | |
|
15:48
araralonre__ joined
|
|||
| moritz | try creating the same thing for JS or Python :-) | 15:48 | |
|
15:51
araraloren_ left
15:53
araralonre__ left
|
|||
| Herby_ | moritz: when is your book's release date? | 16:13 | |
|
16:27
damnlie joined,
TeamBlast left
16:29
TeamBlast joined
16:30
lizmat left
|
|||
| moritz | Herby_: I don't have one yet. but if you sign up for the mailing list, I'll inform you when it's out :-) | 16:33 | |
|
16:36
BenGoldberg joined
16:37
lizmat joined
16:51
_cronus joined
|
|||
| Geth | doc: f62e8604b1 | (Jan-Olof Hendig)++ | doc/Language/regexes.pod6 Fix a couple of typos |
16:54 | |
| _cronus | hello. I have been following perl6 introduction at perl6intro.com/. In 9.10. Introspection I tried to access $!name from Employee class but got "Attribute $!name not declared in class Employee" but it shows in the output of say $jane.^attributes; It probably is too early for me to ask such questions, but I'm curious about the rationality behind this. | 16:59 | |
|
17:02
domidumont joined
17:12
vetmaster joined
|
|||
| jnthn | _cronus: Attributes are private to the class, and not visible to subclasses. However, since the attribute also declares an accessor in this case, then self.name or $.name will provide access to it. | 17:14 | |
| vetmaster | is there some module like 'difflib' for python? | ||
|
17:14
cdg_ left
|
|||
| vetmaster | as I see, I can use Text::Levenshtein with Inline::Perl5 | 17:16 | |
| _cronus | jnthn: thanks. | 17:18 | |
|
17:18
_cronus left,
CacoS left
17:24
ugjka is now known as Braramble
17:25
Braramble is now known as ugjka
17:26
TeamBlast left
17:27
domidumont left
17:28
vetmaster left
17:29
TeamBlast joined
17:31
troys is now known as troys_
17:48
dct joined
17:49
MasterDuke joined
17:52
espadrine_ left
18:09
hankache joined
18:10
TeamBlast left
18:11
TeamBlast joined
18:13
cyphase left,
hankache left
18:15
zakharyas left
18:16
kyan joined
18:17
hankache joined
18:18
cyphase joined
18:23
zapwai joined
18:26
eliasr left
18:27
hankache left
18:28
hankache joined
18:30
jameslenz left
18:40
jameslenz joined,
pecastro left
18:45
CacoS joined
18:47
mcmillhj joined
18:50
Skarsnik joined
18:51
pecastro joined
18:52
mcmillhj left
18:57
Alexdani` joined,
pecastro left
19:00
Alexdaniel left
19:02
pecastro joined
19:03
Alexdani` left
19:11
setty1 joined
19:13
zakharyas joined
19:22
hankache left
19:24
zakharyas left
19:35
labster joined
19:36
_cronus joined
19:41
kaare_ left,
kaare_ joined
|
|||
| _cronus | hello. I've been following the perl introduction at perl6intro.com/#_native_calling_interface. I created the C function, copiled it and linked it to libncitest.so. Running ncitest.pl6 I get 'Cannot locate native library '/home/cronus/perl6intro.com/ncitest.so': /home/cronus/perl6intro.com/ncitest.so: cannot open shared object file: No such file or directory' | 19:43 | |
| after renaming libncitest.so to ncitest.so it works. | 19:44 | ||
|
20:00
Alexdani` joined,
BenGoldberg left
|
|||
| Geth | doc: 56ee890330 | (Jan-Olof Hendig)++ | doc/Language/quoting.pod6 Fixed a few typos |
20:01 | |
|
20:03
TeamBlast left
20:04
Alexdani` is now known as AlexDaniel
20:05
TeamBlast joined
20:07
ggoebel joined,
zakharyas joined
|
|||
| Geth | ecosystem: 68cdcb2629 | (Zoffix Znet)++ (committed using GitHub Web editor) | META.list Add Temp::Path to ecosystem "Make a temporary path, file, or directory": github.com/zoffixznet/perl6-Temp-Path |
20:08 | |
|
20:08
vetmaster joined
|
|||
| vetmaster | is it good to port perl5 modules to perl6? | 20:09 | |
| or it is better to use Inline::Perl5? | |||
|
20:10
Zoffix joined
|
|||
| moritz | depends on what you want | 20:10 | |
| Zoffix | vetmaster: it's best to redesign from scratch. Mere carbon-copy ports in my experience suck badly. | ||
| vetmaster: so if all you wanted to do is to just convert the code to Perl 6, then IMO just use Inline::Perl5. | 20:11 | ||
| moritz | if you want to get started quickly, and are OK with the more complex deplyoments from Inline::Perl5, that's the faster approach | 20:12 | |
| but often Perl 6 offers some features (such as named arguments) that can really improve APIs | |||
| Zoffix | vetmaster: not to toot my own horn, but compare File::Temp that's a port of a Perl 5 module to Temp::Path ( github.com/zoffixznet/perl6-Temp-Path ). File::Temp gives you a string and an open IO::Handle. In Perl 5 handles auto-closed on scope leave, but in Perl 6 they aren't. Perl 5 has no core path object, but Perl 6 has IO::Path. So with File::Temp you're stuck with a string that's not really what you | 20:14 | |
| want and a handle that's you're forced to close. | |||
| Also File::Temp has a bug where it'll delete a potentially good file if you `chdir`. | |||
| Presumable Perl 5's version doesn't have that bug. | |||
|
20:14
zakharyas left
|
|||
| MasterDuke | vetmaster: btw, if you're looking for a string difference/distance module, there's Text::Diff::Sift4 (caveat, i wrote it) | 20:15 | |
| yoleaux | 00:09Z <Zoffix> MasterDuke: something about '-'.IO.slurp.... No idea. Don't have time ATM to look. File a ticket, I'd think | ||
| MasterDuke | yoleaux: that's old news | ||
| Zoffix | I fixed that bug already | 20:16 | |
| AlexDaniel | vetmaster: and I should tell ya, Text::Diff::Sift4 is relatively fast! (caveat, I optimized it) | ||
| vetmaster | then, are Python modules worth porting to Perl6? | ||
| AlexDaniel | mostly, yes | 20:17 | |
| so that you can have perl6-ish API | |||
| vetmaster | so, Inline::Python doesn't work fast and comfortly enough | ||
| ? | |||
|
20:19
BenGoldberg joined
|
|||
| nine | vetmaster: Inline::Python could use some love. There are a couple of performance optimizations I should port from Inline::Perl5 and also a lot of features. | 20:23 | |
| Zoffix | vetmaster: that's subjective, isn't it? It's also a chicken-and-egg situation: if no one uses it because it's slow and uncomfortable, no one is motivated to make it faster and comfortable :) | ||
| BenGoldberg | _cronus, What happens if you replace "$*CWD/ncitest" with "ncitest" | ||
| nine | vetmaster: That said, it may still be ok, depending on your use case. Also my motivation for improving depends on user feedback :) | ||
|
20:23
TeamBlast left
20:25
TeamBlast joined
|
|||
| _cronus | BenGoldberg: I get 'Cannot locate native library 'ncitest.so': ncitest.so: cannot open shared object file: No such file or directory' | 20:26 | |
| BenGoldberg | Hmm... | ||
| BenGoldberg thought that NativeCall automatically prepended 'lib' on linux. | 20:27 | ||
| Zoffix | _cronus: what OS are you on? | ||
| nine | The tutorial really should use %?RESOURCES for referencing the native lib | 20:28 | |
|
20:28
bpmedley joined
|
|||
| _cronus | BenGoldberg: ubuntu 16.04 using using rakudo from the repositories. perl6 -v -> This is perl6 version 2015.11 built on MoarVM version 2015.11 | 20:29 | |
|
20:29
vetmaster left
|
|||
| Zoffix | oooph | 20:30 | |
| That's ancient | |||
| That's even pre-first-release release. | |||
| huggable: debs | |||
| huggable | Zoffix, nothing found | ||
| nine | BenGoldberg: NativeCall will not modify the library name if it already has a file extension. | ||
| Zoffix | huggable: stop losing factoids! | ||
| huggable | Zoffix, nothing found | ||
| Zoffix | huggable: deb | ||
| huggable | Zoffix, CentOS, Debian, Fedora and Ubuntu Rakudo packages: github.com/nxadm/rakudo-pkg/releases | ||
| Zoffix | _cronus: ^ I suggest you upgrade. You're basically using a beta release of perl 6. | ||
| BenGoldberg | nine, I'm not suggesting he add an extension. That's NativeCall's job. | 20:31 | |
| Zoffix | .oO( he? ) |
20:32 | |
|
20:35
d4l3k_ joined,
ChanServ sets mode: +v d4l3k_,
Zoffix left
|
|||
| _cronus | Zoffix: I'll do that. thanks. | 20:35 | |
|
20:37
geekosaur left
|
|||
| BenGoldberg | huggable, source | 20:38 | |
| huggable | BenGoldberg, See github.com/zoffixznet/huggable | ||
|
20:39
geekosaur joined
|
|||
| BenGoldberg | .tell Zoffix you might want to change huggable so that if someone asks for a nonexistant factoid, it asks "Did you mean... {a list of the most similarly named ones}?" | 20:41 | |
| yoleaux | BenGoldberg: I'll pass your message to Zoffix. | ||
| _cronus | BenGoldberg: Seems you were right, just upgraded to 20170300-03 and it automatically adds lib prefix. | ||
| BenGoldberg | _cronus :) | ||
| AlexDaniel | yay | 20:42 | |
| BenGoldberg | What a difference two years worth of upgrades makes ;) | ||
|
20:42
diegok joined
|
|||
| AlexDaniel | BenGoldberg: there's also this: github.com/zoffixznet/perl6-IRC-Cl...d/issues/3 | 20:42 | |
| BenGoldberg: but yeah, create an issue there | 20:43 | ||
|
20:43
integral_ joined
20:44
vetmaster joined,
Bucciarati_ joined
20:45
TeamBlast left
20:46
Khisanth left,
perigrin_ left,
diego_k left,
dalek left,
integral left,
mrsolo left,
chee left,
unclechu left,
NeuralAnomaly left,
k-man left,
ilbelkyr left,
Bucciarati left,
SmokeMachine left,
BuildTheRobots left,
isacloud left,
_cronus left,
d4l3k_ is now known as dalek
20:47
chee joined,
perigrin joined,
Khisanth joined,
mrsolo joined,
NeuralAnomaly joined,
SmokeMachine joined,
isacloud joined,
weber.freenode.net sets mode: +v NeuralAnomaly,
k-man joined
20:48
Mithaldu left,
TeamBlast joined,
mr-foobar left
20:49
notbenh left,
CIAvash[m] left,
M-Illandan left,
mienaikage left,
ilmari[m] left,
xui_nya[m] left,
tadzik left
20:50
dp[m] left,
BuildTheRobots joined,
ilbot3 left,
Matthew[m] left,
mr-foobar joined
20:51
Mithaldu joined,
notbenh joined
20:52
ilbelkyr joined
20:54
ilbot3 joined,
ChanServ sets mode: +v ilbot3
21:00
vetmaster left,
rindolf left
21:03
mienaikage joined
21:07
TeamBlast left
21:10
TeamBlast joined
21:21
CacoS left
21:27
tadzik joined,
unclechu joined,
CIAvash[m] joined,
Matthew[m] joined,
dp[m] joined,
M-Illandan joined,
ilmari[m] joined,
xui_nya[m] joined
|
|||
| Geth | doc: b33dd06206 | (Zoffix Znet)++ (committed using GitHub Web editor) | doc/Type/Iterator.pod6 Document Iterator protocol forbids… …trying to fetch data after IterationEnd |
21:45 | |
| BenGoldberg | . o O (Here be nasal demons) | 21:48 | |
| Geth | doc: 7ff09c8fc4 | (Zoffix Znet)++ (committed using GitHub Web editor) | doc/Type/Iterator.pod6 Misspell behaviour on purpose |
21:56 | |
| doc: 27a9d5b999 | (Zoffix Znet)++ (committed using GitHub Web editor) | doc/Type/Iterator.pod6 And un-defed the undefined |
21:57 | ||
|
22:02
dct left
22:05
dct joined
22:11
travis-ci joined
|
|||
| travis-ci | Doc build failed. Zoffix Znet 'Misspell behaviour on purpose' | 22:11 | |
| travis-ci.org/perl6/doc/builds/239405983 github.com/perl6/doc/compare/b33dd...f09c8fc446 | |||
|
22:11
travis-ci left
22:13
travis-ci joined
|
|||
| travis-ci | Doc build failed. Zoffix Znet 'And un-defed the undefined' | 22:13 | |
| travis-ci.org/perl6/doc/builds/239406257 github.com/perl6/doc/compare/7ff09...a9d5b99972 | |||
|
22:13
travis-ci left
22:20
dct left
22:26
wamba left
22:30
zapwai left,
Skarsnik left
|
|||
| BenGoldberg | m: dd &say.HOW.^methods; | 22:39 | |
| camelia | X::Method::NotFound exception produced no message in block <unit> at <tmp> line 1 |
||
|
22:39
pmurias left,
raschipi joined
|
|||
| BenGoldberg | bisectable6: dd &say.HOW.^methods; | 22:40 | |
| bisectable6 | BenGoldberg, Bisecting by output (old=2015.12 new=36bc410) because on both starting points the exit code is 1 | ||
| BenGoldberg, bisect log: gist.github.com/173d2aa73de9585f25...7c27daabd5 | |||
| BenGoldberg, (2016-09-27) github.com/rakudo/rakudo/commit/22...0f14b9c05c | |||
|
22:42
troys_ is now known as troys
22:43
raschipi left
22:48
kyan left
22:53
nadim left
23:00
mcmillhj joined
23:02
kyan joined
|
|||
| AlexDaniel | bisectable6: old=2016.10 dd &say.HOW.^methods; | 23:11 | |
| bisectable6 | AlexDaniel, Bisecting by output (old=2016.10 new=36bc410) because on both starting points the exit code is 1 | ||
| AlexDaniel | oh come on… | 23:12 | |
| bisectable6 | AlexDaniel, bisect log: gist.github.com/f81037913bb6dbc8e0...efaf79d148 | ||
| AlexDaniel, (2017-06-01) github.com/rakudo/rakudo/commit/c8...3cb5fd2068 | |||
|
23:12
Rawriful left
|
|||
| AlexDaniel | BenGoldberg: maybe you wanted to find this change ↑ | 23:12 | |
| BenGoldberg: see this for a bigger picture: gist.github.com/77cf4168ade069b00d...35085128e9 | |||
| note to everyone: use committable first with “releases” or “all”, then bisect. Otherwise you have no idea what you're bisecting, and looking through the log normally does not help | 23:14 | ||
| MasterDuke: ↑ maybe you're interested in this change | 23:15 | ||
| BenGoldberg | What a huge variety of different error messages :( | 23:18 | |
| m: my &foo; &foo = &say; dd &foo.VAR; &foo = Nil; dd &foo.VAR; | 23:26 | ||
| camelia | Sub.new Invocant of method 'perlseen' must be an object instance of type 'Mu', not a type object of type 'Callable'. Did you forget a '.new'? in block <unit> at <tmp> line 1 |
||
| BenGoldberg wonders what .perlseen is | |||
| Not to mention, isn't everything a Mu? | 23:27 | ||
| geekosaur | loop detection aid, I think. and, the point there is object instance vs. type object, not Mu vs. Callable | ||
| that additional information is presented to help identify where the error occurs, although here you'd need --ll-exception to deal because it's an internal glitch | 23:28 | ||
|
23:32
kyan left
23:42
mcmillhj left
23:45
kyan joined
23:56
d4l3k_ joined,
ChanServ sets mode: +v d4l3k_
|
|||
{kind=link}
{kind=link}