|
🦋 Welcome to the MAIN() IRC channel of the Raku Programming Language (raku.org). Log available at irclogs.raku.org/raku/live.html . If you're a beginner, you can also check out the #raku-beginner channel! Set by lizmat on 6 September 2022. |
|||
|
00:00
reportable6 left
00:02
reportable6 joined
00:06
simcop2387 left,
perlbot left
00:07
simcop2387 joined
00:08
perlbot joined
|
|||
| rf | So turns out you need === defined for CArray[my_cstruct_type] to work | 00:28 | |
| === (Str $foo, my_cstruct_type $bar) | |||
|
00:33
derpydoo joined
01:03
xinming left
01:06
xinming joined
01:11
clsn_ joined
02:11
evalable6 left,
tellable6 left,
bloatable6 left,
statisfiable6 left,
benchable6 left,
squashable6 left,
sourceable6 left,
shareable6 left,
bisectable6 left,
releasable6 left,
unicodable6 left,
committable6 left,
quotable6 left,
nativecallable6 left,
reportable6 left,
linkable6 left,
notable6 left,
greppable6 left,
coverable6 left,
quotable6 joined,
nativecallable6 joined,
sourceable6 joined,
linkable6 joined,
notable6 joined
02:12
tellable6 joined,
shareable6 joined,
committable6 joined,
reportable6 joined
02:13
greppable6 joined,
squashable6 joined,
bisectable6 joined,
statisfiable6 joined,
coverable6 joined,
bloatable6 joined
02:14
benchable6 joined,
evalable6 joined,
releasable6 joined,
unicodable6 joined
02:25
MasterDuke left
02:31
rf left
02:38
codesections left
03:31
Xliff left
03:46
swaggboi left
04:05
swaggboi joined
05:05
coverable6 left,
releasable6 left,
benchable6 left,
evalable6 left,
quotable6 left,
bisectable6 left,
shareable6 left,
sourceable6 left,
greppable6 left,
unicodable6 left,
linkable6 left,
reportable6 left,
notable6 left,
committable6 left,
tellable6 left,
bloatable6 left,
squashable6 left,
statisfiable6 left,
nativecallable6 left,
sourceable6 joined,
nativecallable6 joined
05:06
benchable6 joined,
quotable6 joined,
coverable6 joined,
notable6 joined
05:07
releasable6 joined,
bisectable6 joined,
greppable6 joined,
committable6 joined,
unicodable6 joined,
squashable6 joined,
evalable6 joined,
statisfiable6 joined,
shareable6 joined
05:08
linkable6 joined,
reportable6 joined,
bloatable6 joined,
tellable6 joined
05:11
wbvalid joined
05:18
wbvalid left
05:23
jpn joined
05:28
jpn left
06:00
reportable6 left
06:02
reportable6 joined
06:49
teatime joined
06:52
teatwo left
07:16
Sgeo left
07:29
Max51 joined
07:30
Max51 left
07:45
jpn joined
08:04
jpn left
08:06
jpn joined
08:24
jpn left
08:35
abraxxa joined
08:37
simcop2387 left
08:38
simcop2387 joined,
perlbot left
08:40
perlbot joined
09:04
discord-raku-bot left
09:05
discord-raku-bot joined
09:41
ab5tract joined
09:45
jpn joined
|
|||
| tbrowder__ | g'day, all. does anyone have a working workflows/windows.yml for modules on github? | 11:02 | |
|
11:13
linkable6 left,
evalable6 left
11:14
linkable6 joined,
evalable6 joined
|
|||
| Nemokosch | wouldn't bet my life on that, good sir. But hope dies last | 11:16 | |
| tbrowder__ | 👍🏻 | 11:48 | |
|
11:50
petro-cuniculo joined
11:53
gcd left
11:57
petro-cuniculo left
12:00
reportable6 left
12:03
reportable6 joined,
abraxxa left
13:03
linkable6 left,
evalable6 left
13:06
evalable6 joined,
linkable6 joined
13:43
rf joined
|
|||
| rf | Morning folks | 13:43 | |
|
13:44
jgaz joined
13:46
jpn left
13:49
jpn joined
|
|||
| Anton Antonov | @rf Morning, you, Haskel apologist ! | 13:50 | |
| And monad-promoter… | 13:52 | ||
| Voldenet | Promises are monads and they're everywhere | 13:53 | |
| monad-ish | 13:54 | ||
| rf | Anton :P | 13:56 | |
|
13:57
jpn left
14:00
jpn joined
14:05
jpn left
|
|||
| Voldenet | say (await Promise.kept(Promise.kept(42))).WHAT | 14:10 | |
| evalable6 | (Promise) | ||
| Voldenet | this looks more monadish than js impl, that would just return 42 in that case | ||
|
14:10
jpn joined
|
|||
| [Coke] | would appreciate if someone could review the "is it a bug" question in github.com/Raku/doc/issues/4271 | 14:18 | |
| lizmat | my question would be: did it recently change, or has it always been this way? | 14:20 | |
|
14:20
abraxxa-home joined
|
|||
| Nemokosch | why would if ever topicalize? 🤔 | 14:22 | |
| lizmat | yeah, it feels like an implementation detail | ||
| Nemokosch | > The with statement is like if, but tests for definedness rather than truth, and it topicalizes on the condition, much like given: | 14:26 | |
| so sounds like the documentation contradicts itself | 14:27 | ||
| > You may intermix if-based and with-based clauses. this is the interesting part... | 14:28 | ||
| m: if 0 { .say } orwith Nil { .say } else { .say } | |||
| Raku eval | Nil | ||
| Nil | 14:29 | ||
| Nemokosch | perhaps this is what it's trying to say | ||
| m: if 0 { .say } orwith Nil { .say } elsif 12 { .say } else { .say } | 14:30 | ||
| Raku eval | (Any) | ||
| Nemokosch | this seems surprising to me, though | ||
| the former else clause ran, as an elsif clause, and this time it un-topicalized | |||
|
14:32
jpn left
14:34
jpn joined
|
|||
| rf | Voldenet: Monads are a container with a map and bind | 14:36 | |
| (and return) but that isn't super important | |||
|
14:39
jpn left
|
|||
| rf | Not sure if promise fits it perfectly | 14:39 | |
| dutchie | do you not need return to do the bind/join equivalence | 14:40 | |
| Woodi | rf: but monad-ish can mean "clousure" too ;) | ||
|
14:41
simcop2387 left
14:42
perlbot left,
perlbot_ joined,
simcop2387 joined
|
|||
| rf | Woodi: Not sure what you mean by that | 14:42 | |
| Woodi | rf: just trying to abuse meanings becouse of some similiarities :) | 14:43 | |
| not even sure what "bind" is, too lispy :) | |||
|
14:43
perlbot_ is now known as perlbot
|
|||
| rf | bind : M a -> (a -> M b) -> M b | 14:43 | |
| Woodi | so M is domain of values ? | 14:44 | |
| and result is which part ? | |||
| but assumed functions... | 14:45 | ||
| rf | M is a monad, a is the type held within the monad | ||
| Nemokosch | let's keep it simple | 14:48 | |
| which operation returns a monad, and which a value? | |||
| rf | Bind always returns a monad | 14:49 | |
| Woodi | whay it is doubled ? a -> M b -> M b ? | 14:50 | |
| rf | (a -> M b) is another function | 14:51 | |
| Woodi | then what -> means ? | 14:52 | |
| rf | en.wikipedia.org/wiki/Partial_application | 14:53 | |
| exp | lol a wikipedia page on computer science is not going to make things any more understandable | 14:54 | |
| they unironically care only about number of facts expressed, not how many people understand what's written | |||
| Woodi | so bind is function that returns monad that changes values into ... ? | 14:55 | |
| I thinked about bind in Lisp like some kind of pointer... | 14:56 | ||
| Nemokosch | oh | ||
|
14:56
jpn joined
|
|||
| so bind is the one that takes a function that constructs the new monad directly | 14:56 | ||
| dutchie | if we stick to just talking about promises, bind corresponds to the thenmethod | ||
| then method | |||
| Nemokosch | the then method, when you directly return a Promise in the callback | 14:57 | |
| dutchie | yeah exactly | ||
| the callback is the a -> M b | |||
| Woodi | partial application describes curring ? | 14:58 | |
| dutchie | the invocant is the M a which gets "unwrapped" and fed into the callback | ||
|
14:58
perlbot left,
simcop2387 left
|
|||
| Nemokosch | Promise.resolve(42).then(x => { const funky = Math.random()*x; return Promise.resolve(funky); }) | 14:58 | |
| in pseudocode that absolutely isn't Javascript ^^ | 14:59 | ||
| dutchie | Woodi: they are closely related yes. a "curried" function takes multiple args by returning another function with those args "partially applied" | ||
| some people are more precise than others in keeping the two terms distinct | |||
| Woodi | dutchie: my math teacher said: understand and then memorize or memorize and then understand :) | 15:00 | |
| Nemokosch | yeah I guess think of Haskell | 15:01 | |
| from what I know, Haskell only has functions that take one argument | 15:02 | ||
| Woodi | so looks curring use partial application or even is p.a. ... | ||
| Nemokosch: only one ? crazy :) | 15:03 | ||
| tellable6 | Woodi, I'll pass your message to Nemokosch | ||
| Nemokosch | I don't know Haskell syntax but going by this logic, a function that "takes several parameters", would be called like f(1)('asd')(True) | ||
|
15:04
perlbot joined
|
|||
| where f would return a new function that would return a new function that would return.... you get the idea | 15:04 | ||
| Woodi | sounds in order ;) | ||
|
15:05
simcop2387 joined
|
|||
| Nemokosch | and on each call, the current parameter is built into the returned function | 15:05 | |
| at which point it's just a matter of approach if you say "it has n unbound variables" or you say it's an nth order function | 15:06 | ||
|
15:10
Sgeo joined
15:11
tbrowder_ joined
|
|||
| rf | Nemo bind will "unwrap" the first monad and feed the unwrapped value to a new function (the second parameter) which returns a new monad | 15:12 | |
| github.com/rawleyfowler/Monad-Resu...lt.rakumod | |||
| ^ That repo implements a monad if you;re interested Woodi | 15:14 | ||
| Also Nemo you are correct a function call in Haskell is like f(foo)(bar)(baz) | 15:15 | ||
| Anton Antonov | @Voldenet "Promises are monads and they're everywhere" -- you are on record, I will verify the monad axioms on promises (and be vocal if you wrong.) | 15:21 | |
| @Voldenet "monad-ish" -- nice escape (from rigorous feedback.) | 15:22 | ||
| rf | Hahahaha | 15:23 | |
|
15:25
grondilu joined
|
|||
| Anton Antonov | @rf I considered working on a post that criticizes your monad approach. Diced to postpone it indefinitely. | 15:25 | |
| rf | I am not opposed to counter ideas, though, I haven't heard a compelling one against monads yet. | 15:26 | |
| Voldenet | I once said about that about js since "ye it's mostly monads" but then it wasn't using composition properly | ||
| because then(a).then(b) is different depending on whether return value is Promise or not | 15:27 | ||
| rf | then is map | ||
| Voldenet | from then(x=>a(b(x))) | ||
| Woodi | rf: checking | ||
| Anton Antonov | @rf My point of view on monads is how much a monadic system (e.g. a Raku package) makes the code written with it to have algebraic properties. | ||
| Voldenet | hence my test above | ||
| say (await Promise.kept(Promise.kept(42))).WHAT | |||
| evalable6 | (Promise) | ||
| Voldenet | it's at least not as bad as js | 15:28 | |
| rf | Anton: I am more interested in abstracting side-effects than algebraic properties | ||
| It benefits the consumers of code to use Monadds as well so you can describe the intent of the code | 15:29 | ||
| Voldenet | I bet you can sort of do algebraic effects in raku if you like pain | 15:30 | |
| Anton Antonov | @rf Sure. But, I leverage the algebraic properties when I make translations from natural language DSLs into programming language DSLs. (And vice-versa.) Hence, the algebraic properties for me are important. | ||
| Voldenet | and .throw/.resume combo | ||
| Anton Antonov | @Voldenet Dully noted. | ||
| Nemokosch | then is kind of both bind and map, from what I understand | 15:31 | |
| rf | I really dislike exceptions, which is why I made Monad::Result, I think its very gross to make the caller decipher what possible exceptions can be thrown | ||
| then is just map, map : M a -> (a -> b) -> M b | |||
| Nemokosch | well, then join me on the dark side and let's dislike control exceptions together 😛 | 15:32 | |
| rf | CATCH { default } on every block is just as bad IMO | ||
| Plus it's not enforced or implied so uncaught exceptions are far too common | |||
| Nemokosch | false negatives are worse than false positives with this really | 15:33 | |
| when you only see that some of your assumptions didn't hold | |||
| Anton Antonov | @rf You and @Nemokosch but be on the same gray side. (Or same far side gallery.) | ||
| Woodi | rf: "exceptions" looks like "sudden explosions" :) but concept of shortcuts in execution flow should be usefull... if we have good behaving code like calculations... | 15:34 | |
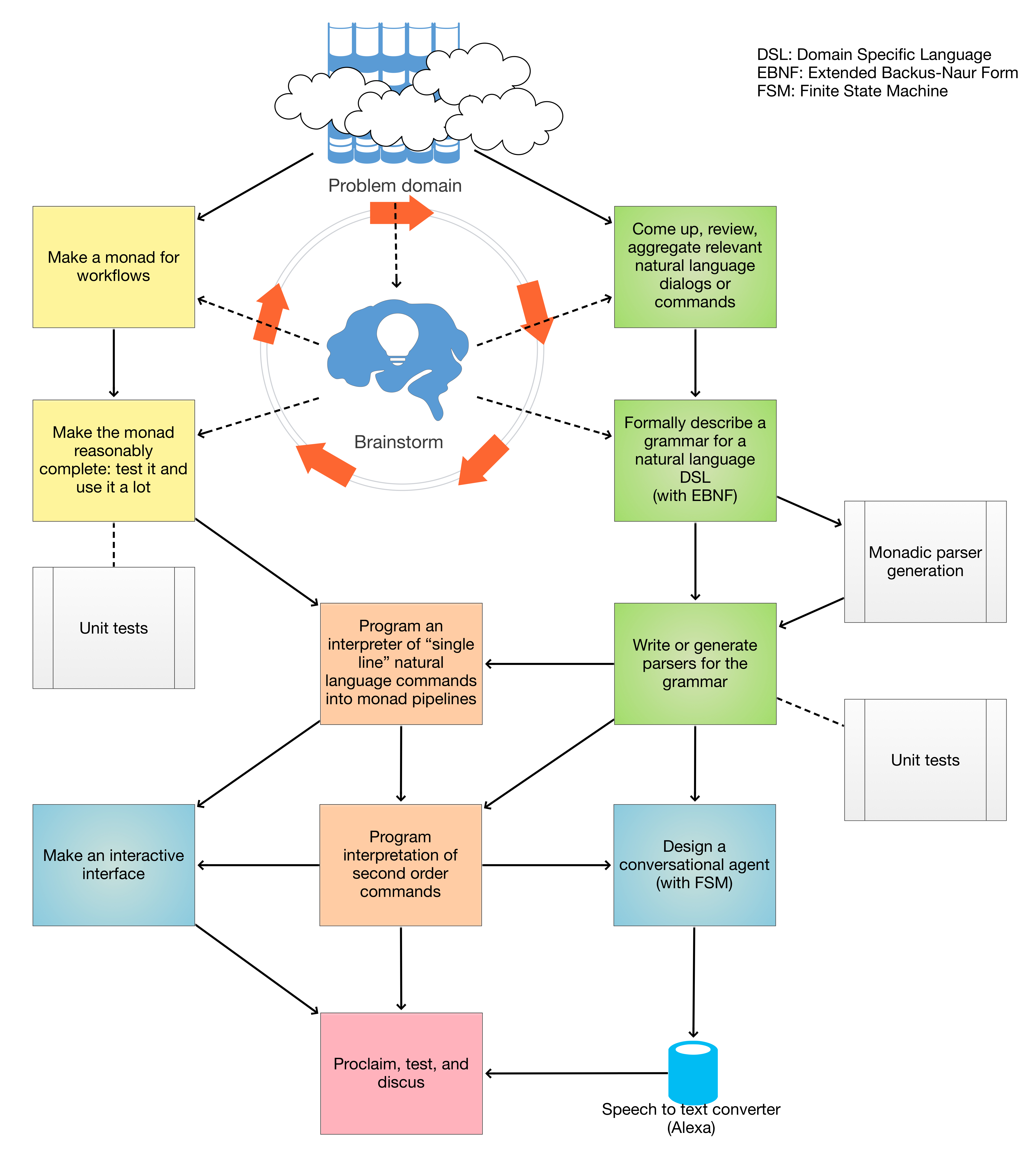
| Anton Antonov | @rf @Voldenet Here is a (very schematic) flowchart of my monads-for-DSLs workflow: raw.githubusercontent.com/antononc...agents.jpg | ||
| rf | That is an interesting approach | 15:36 | |
| Woodi: Most software I write needs to be triple redundant and have 0 exceptions, thus why I prefer monads over exceptions. Shortcuts can simply be expressed as function composition assuming the types align | 15:37 | ||
| Which is also one of the main concepts behind Humming-Bird ^ | |||
| Voldenet | m: class Effect is Exception { has $.x is rw; }; CATCH { when Effect { .x = 42; .resume; } }; my $x = Effect.new; $x.throw; say $x.x | 15:38 | |
| camelia | 42 | ||
| Voldenet | I'm begging you, don't use the above thing | ||
| it sort of works though | |||
| rf | Anton you are the first ML person I have heard even use the word Monad :D | 15:39 | |
| Anton Antonov | @rf Basically, if I can use "your" monads if I can put the operations in a reduce statement. For example, reduces(&my-monad-bind, my-monad-unit-object(), [&some-op1, &some-op2, &some-op3, &take-value] ) . | ||
| rf | Yes that should work | 15:40 | |
| Anton Antonov | @rf Ok, good. (Meaning, "you are on record and will try to verify.") | 15:41 | |
| @rf ML people use monads, but they do not know and/or use the terminology. | 15:42 | ||
| rf | As long as your ops are -> M a -> (a -> M b) -> M b | ||
| Voldenet | most people use monads and algebraic effects | ||
| Anton Antonov | @rf Right, the associativity rule. | ||
| Voldenet | they just buried in N layers of their language abstraction | ||
| s/they/they're/ | 15:43 | ||
| Anton Antonov | @Voldenet Most Data Science people do not want to program. So, whatever simplifications are used to make the required work more palatable. | 15:44 | |
| Voldenet | I remember showing my data sci. code to data scientist, he scratched his head and said he didn't get the code :/ | 15:46 | |
| (I tried to abstract away data science part so I could get to my programming one…) | |||
| Anton Antonov | @Voldenet Right, hence, I make/use natural language DSLs for Data Science. They still say the same. | 15:47 | |
| Voldenet | that makes sense | ||
| Anton Antonov | Hopefully, I am not overestimating the interest in this -- here is an example of data wrangling Python code generation from sequences of natural language commands: github.com/antononcube/RakuForPred...thon.ipynb | 15:51 | |
| Or, if you prefer, the Raku code results version: github.com/antononcube/RakuForPred...Raku.ipynb | 15:52 | ||
|
15:57
perlbot left
15:58
simcop2387 left
16:01
perlbot joined
16:02
simcop2387 joined
|
|||
| clsn_ | So. Haven't worked with raku in a *long* time, and some things have changed. Right now, I can't see how it's possible to make a regex that matches a *combining* character (or set thereof). I can only match base characters and specify combining characters on them if I want, but I'm searching for the actual combining character which may be on any of many bases (and may even have other combining chars with it.) | 16:54 | |
| This is not an unrealistic request, by the way. Not everything is like é where the accent isn't something you'd want to search for without the letter. I'm working with Hebrew cantillation marks, which are like punctuation that happen to be written as combining characters. | 16:56 | ||
| m: my $x="עֵֽינֵיכֶ֑ם"; say $x ~~ /\x[0591]/; | 16:59 | ||
| camelia | Nil | ||
|
17:02
linkable6 left,
evalable6 left
17:03
linkable6 joined
17:04
evalable6 joined
|
|||
| Nemokosch | strings are normalized according to NFC | 17:09 | |
| clsn_ | Yes, which is fair enough... But rakudo, from what I've seen, matches stuff according to its "NFG". How might I write a regex that can match the 0591 in that string? NFC vs NFD isn't really relevant; none of the characters there are or can be precomposed. | 17:11 | |
| Nemokosch | I'd expect a regex to operate on the level of characters, not codepoints | 17:14 | |
| clsn_ | Well, from a Unicode perspective, \x[0591] is a character, so I'm not sure what you mean. If you mean by graphemes, that sort of presumes that it doesn't make sense to search for an \x[0591] because it is written as a diacritic, yet that makes just as little sense as saying that it doesn't make sense to search for a comma in a sentence. | 17:15 | |
| Nemokosch | I'm not sure if it's still a character after NFC | 17:17 | |
| but sure thing, definitely not a grapheme, and a high-level string has characters as graphemes | |||
|
17:18
codesections joined
|
|||
| clsn_ | NFC, as I understand it, is "combine everything that can be combined into precomposed characters," and nothing in the example string can make up a precomposed character. Am I misunderstanding you? | 17:18 | |
| Well, then, how would I write a grammar to search for it? It may not be written as a spacing character, but it is exactly as reasonable to search for it as it is to search for a comma or semicolon in English text. | 17:19 | ||
| Nemokosch | This is probably beyond me. There is stuff like this docs.raku.org/type/Uni.html | 17:23 | |
| but whether it works with regex stuff, no clue | 17:24 | ||
| clsn_ | So I could convert it to something more unicode-ish, but can I then use regex--- I see. | ||
| This is actually for pretty much the ONLY program I've ever written in rakudo, apart from contributions I made to the actual project. And it *used* to work. Many years ago. | 17:25 | ||
|
17:26
cfa joined
|
|||
| cfa | bisectable6: my $x="עֵֽינֵיכֶ֑ם"; say $x ~~ /\x[0591]/; | 17:26 | |
| bisectable6 | cfa, Will bisect the whole range automagically because no endpoints were provided, hang tight | ||
| cfa, ¦6c (67 commits): «Nil» | |||
| cfa, Nothing to bisect! | |||
| Nemokosch | that must have been a lot of years ago for sure | 17:27 | |
| probably prior to MoarVM, and MoarVM has been the state of art runtime since like 2013 | |||
| clsn_ | It was a REALLY long time ago; I'm not sure I can find quite how long it was. Eh, I probably have logs someplace... | ||
| Nemokosch | anyway, now I'm not convinced that it is intended to work | 17:28 | |
| clsn_ | Yeah, the latest commit in my repo is from December 2011. | ||
| Nemokosch | there is a candidate for smartmatching Uni against Regex github.com/rakudo/rakudo/blob/2022...ex.pm6#L47 but it basically converts to Str and calls it a day | 17:29 | |
| clsn_ | It may or may not be "right" for it to work *as stated*, but I think there definitely needs to be some way to make it work, or you're really missing something important. | ||
| i.e. converting to some form or another that regex-matches on codepoints or something like that. | 17:30 | ||
| Nemokosch | what I doubt, though, is that this is high-level enough to fall into regex territory | ||
| clsn_ | s/i\.e\./e.g./ (can't believe I used \ for that...) | ||
| Nemokosch | yeah that sounds horrible tbh, to replace a part of a grapheme | 17:31 | |
| clsn_ | Well, I still contend that if regexes can't do it in any fashion, then you're failing to capture or make available something very important and not unreasonable for people to want to do. I present my own program as evidence of that (granted, one might argue that I only barely qualify as "people"...) | 17:32 | |
| I could easily see someone studying Hebrew or Arabic doing searches for vowel-patterns (which indicate grammatical forms). | |||
| Nemokosch | well I'm just saying that it perhaps doesn't fall into regex territory | ||
| clsn_ | and the Hebrew Bible cantillations are part of a well-understood and well-defined grammar. | 17:33 | |
| Not certain what that really means, or if that answers. You can do that, you just can't use regexes for it? And yet it's matching patterns in a string of characters, isn't that what regexes are supposed to do for a living? Why should someone have to write up their own homegrown regex-matcher just for certain kinds of characters? | 17:34 | ||
| Nemokosch | they are not "characters" on Str level | 17:36 | |
| clsn_ | My program from way back when would parse a Biblical sentence according to the structure of sentential breaks encoded by the cantillations and output a tree graph in dot format. That's parsing text with a grammar. | ||
| Nemokosch | And like, regex is not meant for any pattern matching. For example, you can't just arbitrarily match binary patterns in the unicode representation | 17:37 | |
| I mean, sorry for your loss | |||
| cfa | here's another example, | 17:38 | |
| m: say "u\x[0308]" ~~ /\x[0308]/ | |||
| camelia | Nil | ||
| clsn_ | web.meson.org/cache/Esth:8:9.png | ||
| Nemokosch | But I'm not convinced that this is a problem with the regex itself, as it clearly works on the principle that a character is a grapheme | ||
| clsn_ | I can see that this is a limitation of the way rakudo has chosen to define strings and regexes. But I wonder if that choice is defensible in the face of, well, not being able to do exactly what regexes and grammars are supposed to do. | 17:39 | |
| Nemokosch | frankly I don't know about Unicode enough to understand what makes a "combining character" a "character", in this jargon | ||
| Again, I don't think regexes (let alone grammars) are supposed to dig this deep | 17:40 | ||
| clsn_ | Eh, that's because "character" sounds like it should be some graphical unit, i.e. a grapheme, so it's hard to see a combining character as one. | ||
| Voldenet | if you don't mind performance hit then | ||
| Nemokosch | So what is it exactly, that it isn't just called a codepoint? | ||
| clsn_ | But whyever not? As I said, it's a very reasonable thing to ask a grammar to do. | ||
| Voldenet | m: my $x="עֵֽינֵיכֶ֑ם"; say 0x591 (elem) $x.ords; | 17:41 | |
| camelia | True | ||
| Nemokosch | You said so yes but it didn't sound any different from saying that grammars are for binary inspection. | ||
| clsn_ | In Unicode parlance, character and codepoint can be almost interchangeable. Indeed, I understand what you mean about having trouble seeing it as a character, but coming from a more Unicode-centric POV myself, I find the opposite to be true. | ||
| Nemokosch | Also, you earlier made the distinction from é. ("Not everything is like é where the accent isn't something you'd want to search for without the letter.") | 17:42 | |
| what backs this distinction up, that could be somehow integrated? | 17:43 | ||
| clsn_ | I don't know. Binary patterns are not regex-fodder because they don't generally have structural meaning that's useful for pattern-matching in most strings. Combining characters do. I guess there's some fuzziness in that argument. | ||
| Ah, that's a better question... | |||
| Nemokosch | Yes, this whole fuzziness | ||
| clsn_ | OK, let's see if I can explain what I mean by that, and maybe I'm wrong about the distinction as well... | ||
| Nemokosch | that even though "combining characters" fall back into being codepoints and hence just binary data specified by Unicode, they can matter on textual level sometimes apparently | 17:44 | |
| clsn_ | An é is, in a sense, a letter in itself. That's (kinda) why it has a precomposed codepoint, or at least why it was thought at some point to be worth encoding precomposed and Unicode inherited it. And even if considered as an e plus an acute accent, there's nothing in common between e+acute and a+acute. They're independent of one another. | 17:45 | |
| Nemokosch | > é oof | 17:46 | |
| clsn_ | It's not like it's completely impossible, but it would be an odd situation wherein you'd want to search for words with 3 or more accents or something. | ||
| Do my unicode chars not come through okay? | |||
| Nemokosch | not really. I mean, this is just universally sad. Here we are in 2023 and the best we could get is like, semi-cover fairly similar languages in IT | 17:47 | |
| Voldenet | The problem is that one grapheme can be respresented by multiple codepoints | 17:48 | |
| Nemokosch | anyway. What I think should (and might?) exist is still something like "capture this letter containing codepoint XYZ" | ||
| clsn_ | OTOH, Hebrew and Arabic vowels, for example, or even Devanagari combining vowel marks, are more related to themselves and each other than to the letters they are on. á and é have nothing in common, particularly, but का and गा rhyme, both might represent similar grammatical constructions, etc. | 17:49 | |
|
17:49
cfa left
|
|||
| clsn_ | Ideally not "containing codepoint XYZ" but "containing a regexp(?) of these codepoints" or at the very least "containing a codepoint out of this set". | 17:49 | |
| Nemokosch | ngl this also sounds to me that Unicode itself is either misunderstood or contains problematic concepts | 17:51 | |
| teatime | it is complex for sure | ||
| clsn_ | It's even more so in Hebrew and Arabic. A word that is CONSONANT + QAMATS(05B3) + CONSONANT + PATAH(05B7) + CONSONANT is very distinctly third-person singular masculine past tense, simple construction. | ||
| Nemokosch | like, if this \x[0591] is so useful on its own and an acute accent isn't, why aren't they distinguished on any conceptual level? | 17:52 | |
| clsn_ | I don't need to know what the consonants are, but that's what that word means (there are exceptions and phonological concerns and blahblahblah but to first approximation.) | ||
| 0591 represents the chief sentential pause in the middle of a Biblical verse. | |||
| web.meson.org/cache/Esth:3:12:.svg is an even more extreme example (the longest verse in the Hebrew Bible) | 17:55 | ||
| The cantillations define and determine that tree. Just as one might parse an English sentence on periods and commas and semicolons (but the cantillations are more precisely-defined and fine-grained.) | |||
| From a Unicode perspective, I guess combining characters are combining characters (they do have combining classes, though), and they don't try to distinguish ones which are more or less important than others, probably because they're not suppressing the ones of lesser importance. But here, NFG *does* "suppress" them, in some sense, in that you can't conceive of them without their bearers, and that sucks in the ones that have independent meaning as well. | 17:59 | ||
|
17:59
abraxxa-home left
18:00
reportable6 left
18:01
reportable6 joined
|
|||
| clsn_ | For that matter, I don't think you can even search for "some hebrew letter followed by a TSERE" or whatever (i.e. use a character class for the base.) | 18:03 | |
| Nemokosch | my point is that if they are so important, perhaps they should stand on their own, just like nobody would pretend that a comma or a dot is a combining character | ||
| or any punctuation for that matter | |||
| lizmat | clsn_: :ignoremark ? | ||
| Voldenet | probably ignoremark won't work | 18:04 | |
| lizmat | docs.raku.org/language/regexes.html#Ignoremark | ||
| why wouldn't it ? | |||
| clsn_ | I tried ignoremark. | ||
| lizmat | example? | ||
| clsn_ | That ignores the mark. But I don't want to ignore the mark! I want to search for a specific mark!! | ||
| Voldenet | m: my $x="עֵֽינֵיכֶ֑ם"; say $x ~~ / .<?{ 1497 (elem) $/.ords }> / | 18:05 | |
| camelia | 「י」 | ||
| lizmat | well, then search for the char with :ignoremark, and then check whether it is followed by a TSERE ? | ||
| Voldenet | there's more than one way to do what you want | ||
| <?{ }> is not very elegant solution, but a solution | |||
| Nemokosch | a not very elegant solution to a not very elegant task 😅 | 18:06 | |
| Voldenet | in fact | ||
| m: my $x="עֵֽינֵיכֶ֑ם"; say $x ~~ / .<?{ 1497 == $/.ord }> / | |||
| camelia | 「י」 | ||
| clsn_ | Maybe they should stand on their own. But Unicode considers combiningness from the point of view of graphics, not semantic sense. By adopting that, rakudo has placed ALL the combining characters in the same bucket. If there's a distinction that should be made, it will need to be made in rakudo. | ||
| Nemokosch | > But Unicode considers combiningness from the point of view of graphics, not semantic sense. Holdya holdya. So far, all you said was how you have the Unicode perspective. | 18:07 | |
| Voldenet | current combining characters situation is probably a tradeoff, since combining characters turn elegant constant-time algos into monsters | ||
| clsn_ | I can certainly search codepoint-by-codepoint and find the characters I'm looking for. But then, once more, didn't God create regexes precisely to do this kind of job? I'm looking for the word that contains a \x[0591] in a string of words. How can I do that? | ||
| Voldenet | but the above one _is_ the regex | 18:08 | |
| … :) | |||
| Nemokosch | the only problem with it is that it's slow-ish, really | ||
| Voldenet | you can compose it and put more regexes in it | ||
| clsn_ | That's how I understand what I think Unicode is doing; maybe I'm wrong about that. | ||
| I'm sorry, I'm not seeing how that's working. Expecially since the thing you're matching is a letter without any diacritics. | 18:09 | ||
| Nemokosch | m: my $x="עֵֽינֵיכֶ֑ם"; say $x ~~ / .<?{ 1425== $/.ord }> / | 18:10 | |
| Raku eval | Nil | ||
| Nemokosch | meh, why ord | ||
| clsn_ | Here... here's the whole verse. Please tell me a regex I can use to find the word with the 0591 under it: "כִּ֚י יֹדֵ֣עַ אֱלֹהִ֔ים כִּ֗י בְּיוֹם֙ אֲכָלְכֶ֣ם מִמֶּ֔נּוּ וְנִפְקְח֖וּ עֵֽינֵיכֶ֑ם וִהְיִיתֶם֙ כֵּֽאלֹהִ֔ים יֹדְעֵ֖י טֹ֥וב וָרָֽע׃" | ||
| Nemokosch | m: my $x="עֵֽינֵיכֶ֑ם"; say $x ~~ / .<?{ 1425 (elem) $/.ords }> / | ||
| Raku eval | 「כֶ֑」 | ||
| Nemokosch | this was the better one | ||
| clsn_ | That's the right letter, yes. Maybe one can do this after all? Placing other dummy letters around it? | 18:11 | |
| Nemokosch | this literally does "take the letter and check what it's made of" | ||
| clsn_ | (It's Genesis 3:5, btw; I just picked it arbitrarily when trying this out.) | ||
| hm. so then could I say... | 18:12 | ||
| Nemokosch | in either case, thank you for the journey at least | ||
| Voldenet | m: my $x="כִּ֚י יֹדֵ֣עַ אֱלֹהִ֔ים כִּ֗י בְּיוֹם֙ אֲכָלְכֶ֣ם מִמֶּ֔נּוּ וְנִפְקְח֖וּ עֵֽינֵיכֶ֑ם וִהְיִיתֶם֙ כֵּֽאלֹהִ֔ים יֹדְעֵ֖י טֹ֥וב וָרָֽע׃"; say $x ~~ / (\w<?{ 1497 (elem) $/.ords }>) / | ||
| camelia | 「י」 0 => 「י」 |
||
| Voldenet | perhaps this, but my terminal outputs it all as spaces | ||
| Nemokosch | I wouldn't have thought for the life of me that something that has zero length can be this significant | ||
| Voldenet | that… doesn't help | ||
| Nemokosch | funky, it turned backwards | 18:13 | |
| clsn_ | m: my $x="כִּ֚י יֹדֵ֣עַ אֱלֹהִ֔ים כִּ֗י בְּיוֹם֙ אֲכָלְכֶ֣ם מִמֶּ֔נּוּ וְנִפְקְח֖וּ עֵֽינֵיכֶ֑ם וִהְיִיתֶם֙ כֵּֽאלֹהִ֔ים יֹדְעֵ֖י טֹ֥וב וָרָֽע׃"; say $x ~~/<:Lo>*.<?{ 1497 (elem) $/.ords}<:Lo>*/;' | 18:14 | |
| camelia | ===SORRY!=== Error while compiling <tmp> Unable to parse expression in metachar:sym<assert>; couldn't find final '>' (corresponding starter was at line 1) at <tmp>:1 ------> ay $x ~~/<:Lo>*.<?{ 1497 (elem) $/.ords}⏏<:Lo>*/;' … |
||
| clsn_ | bah, sorry, my rakudo regex-fu is very weak, it's been a looong time. | ||
| The "turning backwards" is probably an artifact of the Bidi algorithm at work in your terminal, which is the cause of much headache and profanity. | 18:15 | ||
| Voldenet | m: my $x="כִּ֚י יֹדֵ֣עַ אֱלֹהִ֔ים כִּ֗י בְּיוֹם֙ אֲכָלְכֶ֣ם מִמֶּ֔נּוּ וְנִפְקְח֖וּ עֵֽינֵיכֶ֑ם וִהְיִיתֶם֙ כֵּֽאלֹהִ֔ים יֹדְעֵ֖י טֹ֥וב וָרָֽע׃"; say $x ~~/<:Lo>*.<?{ 1497 (elem) $/.ords}><:Lo>*/;' | ||
| camelia | ===SORRY!=== Error while compiling <tmp> Unable to parse expression in single quotes; couldn't find final "'" (corresponding starter was at line 1) at <tmp>:1 ------> :Lo>*.<?{ 1497 (elem) $/.ords}><:Lo>*/;'⏏<EOL> expecting … |
||
| Voldenet | m: my $x="כִּ֚י יֹדֵ֣עַ אֱלֹהִ֔ים כִּ֗י בְּיוֹם֙ אֲכָלְכֶ֣ם מִמֶּ֔נּוּ וְנִפְקְח֖וּ עֵֽינֵיכֶ֑ם וִהְיִיתֶם֙ כֵּֽאלֹהִ֔ים יֹדְעֵ֖י טֹ֥וב וָרָֽע׃"; say $x ~~ /<:Lo>*.<?{ 1497 (elem) $/.ords }><:Lo>*/; | 18:16 | |
| camelia | 「כִּ֚י יֹדֵ֣עַ」 | ||
| Voldenet | apparently it works | ||
| clsn_ | Not really, it's the wrong work. | ||
| word. | |||
| Still, it's catching a whole word... um, a whole PAIR of words... which is... is it better than just a letter? | 18:17 | ||
| Wait, 0591 is 1425, not 1427 | |||
| Voldenet | right :D | 18:18 | |
| clsn_ | 1427 is HEBREW ACCENT SHALSHELET, 0593, which is a VERY rare cantillation and certainly not found in this verse. | ||
| You can write 0x0591, right? With hex notation? That'll be less confusing. | |||
| Voldenet | m: my $x="כִּ֚י יֹדֵ֣עַ אֱלֹהִ֔ים כִּ֗י בְּיוֹם֙ אֲכָלְכֶ֣ם מִמֶּ֔נּוּ וְנִפְקְח֖וּ עֵֽינֵיכֶ֑ם וִהְיִיתֶם֙ כֵּֽאלֹהִ֔ים יֹדְעֵ֖י טֹ֥וב וָרָֽע׃"; my regex etnahta { .<?{ 1425 (elem) $/.ords }> }; say $x ~~ /<:Lo>*<etnahta><:Lo>*/; | 18:19 | |
| camelia | 「עֵֽינֵיכֶ֑ם」 etnahta => 「כֶ֑」 |
||
| Voldenet | you could simply do this | ||
| it's probably more sane when you want to compose it | |||
| you can use 0x591 if you want, the `{ 1425 (elem) $/.ords }` is regular subroutine | 18:20 | ||
| clsn_ | Ugh, hard to read because of the Bidi stuff. But still. That... looks right, actually. | 18:22 | |
| Still smacks slightly of not-ideal, but requiring you to use a subroutine just to pick out the combining character you want isn't THAT unreasonable. (though actually, I need to be able to check for any member of a *set* of combining characters, but that's probably generalizable from this.) | 18:24 | ||
| Voldenet | I didn't test this for performance, maybe some form of checking substrings of .encode would've been faster | 18:25 | |
| clsn_ | What you have here is maybe clumsier than it once was, but still has some elegance, thank you. | ||
| Meh, I'm not terribly fussed about performance. Computers are fast enough that even slow for them is still fast, when dealing on the scale and number of instances I'm worried about. | 18:26 | ||
| I'll have to see if/how I can shoehorn this in to my old program, but it looks like a promising path. | 18:27 | ||
|
18:28
grondilu left
|
|||
| clsn_ | Anyway, so thanks very much, and maybe it's something for you to ponder as well. | 18:35 | |
| Voldenet | I've sort of given up from expecting much from unicode | 18:36 | |
| m: "ł".NFD.say | |||
| camelia | NFD:0x<0142> | ||
| Voldenet | common polish letter, l with a stroke, is defined as character, so it would never match l anyhow… | 18:37 | |
| doesn't put high confidence in the standard itself | |||
| clsn_ | Yeah, Unicode has plenty of st00pid in it. Some of it comes from the fact that encoding letters is just plain more complicated than it sounds, but much of it is... well... yeah, st00pid. | 18:39 | |
| They have some tables, I think, for dealing with stuff like what you're talking about in SOME cases, but I'm pretty sure not in that case. Whatever; I'm not here to defend Unicode. I am fully aware of its flaws (some of them; I'm sure it has more I don't know about yet) and will not dispute faults you find in it. | 18:42 | ||
|
18:49
teatwo joined
18:52
teatime left
|
|||
| [Coke] | I'm late, but if you're looking for the accent, then you probably want a different normalized form (with the combining chars split out), and then look for that. | 19:15 | |
| m: say <e á é a>.NFD.grep: 0x0301 | 19:17 | ||
| camelia | (769 769) | ||
| [Coke] | m: say <e á é a>.map(*.NFD).grep(*.grep: 0x0301).map(*.Str) | 19:19 | |
| camelia | (á é) | ||
| [Coke] | there you go, that's more useful. | ||
| you could replace that inner grep with a \c[] with the combining char's name (or the decimal codepoint) or whatever. | 19:22 | ||
| This should also work if any of the graphemes have multiple combining chars. | 19:23 | ||
|
19:29
derpydoo left
19:48
jpn left
|
|||
| [Coke] | www.perlfoundation.org/the-perl--r...rence.html is only showing last year | 19:49 | |
|
19:51
jpn joined
|
|||
| clsn_ | It's not an accent, and it isn't like I can list all the letters it might be on. And it isn't an NFC/NFD thing, because it isn't something that can be precomposed anyway. But thanks! | 19:54 | |
| [Coke] | then you should be able to see it in the ords for that grapheme, no? | 20:03 | |
| (you should be able to skip the NFD step if it doesn't need decomposing, I mean.) | 20:04 | ||
|
20:09
jpn left
|
|||
| clsn_ | You would think. Hm, so use grep instead of ~~? But is that looking through codepoint by codepoint? Which might not be a bad thing, to be fair. | 20:24 | |
| So long as it is done a bit more elegantly than just a for-loop through the whole string! :) | |||
|
20:32
jpn joined
20:39
jpn left
20:43
jpn joined
20:49
jpn left
20:50
rf left
|
|||
| [Coke] | I think this is a raku bug. Tried to install my own module, App::Unicode::Mangler, and got an error line like: | 21:19 | |
| [App::Unicode::Mangle] Please u | |||
| [App::Unicode::Mangle] se uniparse instead. | |||
| I think something is trying to print "nice" whitespace there and failing. | |||
|
21:24
perlbot left,
simcop2387 left,
perlbot joined
|
|||
| [Coke] | m: "e̸".ords.say # see, this has the ords already - if it was combinable, you'd get the combined char here. | 21:24 | |
| camelia | (101 824) | ||
|
21:25
simcop2387 joined
21:30
perlbot left
21:33
perlbot joined
21:40
perlbot left,
perlbot joined
21:54
jpn joined
22:01
jpn left
|
|||
| guifa | is nqp big integer the same as a Raku Int? | 22:13 | |
| [Coke] | ¡nʞɐɹ# 'oʃʃǝH | 22:14 | |
| No nqp types are exactly the Raku types. | |||
| guifa | how can I convert any old Int into a big int for nqp use? I'm trying to find the fastest way to shift the char codes of a string by X | 22:15 | |
|
22:17
simcop2387 left,
simcop2387 joined
|
|||
| lizmat | guifa: why would you need bigints for that ? | 22:28 | |
| guifa | errr, I guess there are actually two separate ops there and my brain is a bit tired hahaha | 22:29 | |
| step one is to do some math on big ints (because I don't want to error if numbers are two big) | |||
| step two is then to shift the char codes by X | |||
| lizmat | how would that look in Raku ? :-) | 22:30 | |
| guifa | the second part, @str.ords.map(* + $adjust-value)>>.chr.join | 22:32 | |
| I've been testing around to see the fasest method | |||
| sorry $str | |||
| lizmat | you realize that .ord will only produce the first codepoint of a grapheme | 22:33 | |
| guifa | Yeah -- in this case, it's a guarantee that it's a single codepoint | ||
| lizmat | ok, check | ||
| so, if $adjust-value is 13, you're doing something like a rot13 | 22:34 | ||
| guifa | $str.trans( <0 1 2 3 4 5 6 8 9> => <a b c d e f g h i j>) is the fastest native Raku method, but has a huge start up penalty, so unless numbers are regularly 100+ digits, the current winner is $new := $new ~ ($_ + 49).chr for ^$a.ords; | ||
| yup | |||
| lizmat | m: use nqp; say nqp::strfromcodes("foo".NFC) # does this give an idea ? | 22:39 | |
| camelia | foo | ||
| Voldenet | `$new := $new ~ ($_ + 49).chr for ^$a.ords` | 22:41 | |
| doesn't it malloc for every character? | 22:42 | ||
| No idea how can this be faster | |||
| lizmat | m: use nqp; my int32 @a; @a.push($_ + 3) for "foo".NFC; say nqp::strfromcodes(@a) | ||
| camelia | irr | ||
| guifa | my int32 @temp; nqp::strtocodes($str, nqp::const::NORMALIZE_NFC, @temp); @temp[$_] += $adj; $str := nqp::strfromcodes(@temp) | ||
| ^^ that's basically about 3% faster than the trans method | 22:43 | ||
| lizmat | only 3% ? | ||
| guifa | that's why I think there should be a faster way | ||
| lizmat | += is generally not the fastest | ||
| guifa | also when I tried nqp::for(…, …) it says it expects a block, but I give it one | 22:46 | |
| lizmat | nqp::for is an interesting beastb :-) | 22:48 | |
| Voldenet | the faster way would be to use cstring, then avx256 sum it with 0x3131313131313131 | ||
| reject sanity, embrace xs | |||
|
22:51
japhb left,
japhb joined
|
|||
| guifa | Voldenet: ha, yeah. I mean, I get I'm basically doing something that's solving a problem Raku wasn't made to solve hahaha | 22:51 | |
| Voldenet: ha, yeah. I mean, I get I'm basically doing something that's solving a problem Raku wasn't made to solve hahaha | 22:52 | ||
|
22:52
ugexe left
|
|||
| guifa | It's just killing me I can't speed up number formatting by much more and probably 40% of it is not being able to do math on strings (understandable, Raku abstracts away a lot of that stuff intentionally) and 40% of it is wanting to supper arbitrarily large numbers | 22:54 | |
| Voldenet | actually I think that stuff like `$str.ords.map(* + 49).map(*.chr).join` could be rewritten into vectorized form | 22:56 | |
|
22:57
jgaz left
|
|||
| Voldenet | on the optimizer leve | 22:57 | |
| Nemokosch | not sure if it would help here but did folks officially give up on moving away from libtommath? | 22:59 | |
| in MoarVM that is | |||
|
23:01
ugexe joined
|
|||
| guifa | Thankfully for formatting with West Arabic digits I can skip the rot'ing, but with any others I'll need to add them in (thankfully, that's an easy optimization) | 23:04 | |
|
23:12
jpn joined
|
|||
| guifa | okay this is ugly as sin but it's def faster | 23:12 | |
| nqp::strtocodes($str, nqp::const::NORMALIZE_NFC, @temp); nqp::bindpos_i(@temp,$_,nqp::add_i(nqp::atpos_i(@temp,$_),$adj)) for ^@temp; $str = nqp::strfromcodes(@temp) | 23:13 | ||
|
23:17
derpydoo joined
23:18
jpn left
|
|||
| guifa | oh nice | 23:19 | |
| changing out that for ^@temp with a my int32 $temp = nqp::elems(@temp); while($temp--, { ^^thatmess upthere }); knocks off another 15-20% | 23:20 | ||
| [Coke] | is there a way to find out if your grapheme will render? | 23:21 | |
| m: "d͖̤ᷛ᷼f͚ͯᷬ̒ ".uninames.say | 23:22 | ||
| camelia | (LATIN SMALL LETTER D COMBINING RIGHT ARROWHEAD AND UP ARROWHEAD BELOW COMBINING DIAERESIS BELOW COMBINING LATIN LETTER SMALL CAPITAL G COMBINING DOUBLE INVERTED BREVE BELOW LATIN SMALL LETTER F COMBINING DOUBLE RING BELOW COMBINING LATIN SMALL LETTER… | ||
| [Coke] | in my local terminal, that's a box with a ? in it. It's valid unicode, but my terminal can't display it. | 23:23 | |
| guifa | not from Raku at least -- you'd need to come up with some way to query the terminal, know what font it will use, and then figure out if the font has that character in its inventory | 23:24 | |
| I think dwarren has some moduels for the font side of stuff | 23:26 | ||
| [Coke] | s͔᷹o̟ᷔ ̵̢ę͚a̴̔s᷻́y͖ᷗ ̟᷽t̝̦o̵͡ ̯᷍gᷙ᷅o᷆̽ ̠ᷦoᷖᷪfᷧ̀f᷺ᷝ ᷇̏t̜̊hᷗ͘e̠͑ ̱ᷰṟᷮa᷇ͪíͭl̲ᷤs̩͍ | 23:28 | |
| so easy to go off the rails | 23:29 | ||
| made some slight improvements to github.com/coke/raku-unicode-mangler - at least it doesn't generate invalid characters now, just a lot of unprintables. :) | |||
| Nemokosch | 😄 | 23:32 | |
{kind=link}
{kind=link}
{kind=link}